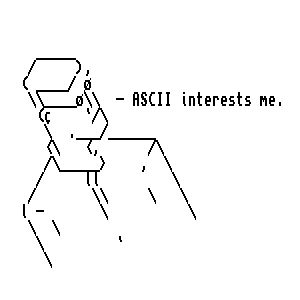
I wrote this piece by hand and photographed the pages. After that, I wanted to make the text copy-pasteable. So I put the images into one SVG file with a text overlay:
Pictured: overlaid + spaced out text. Notice the ` spacers and extra spaces.
The font (Barlow Condensed – Italic Condensed) and the line height roughly match my handwriting’s dimensions. For spacing, the idea was that I’d add spacing characters that’ll be removed in Javascript during the copy-paste event that fires on the webpage.
I used ` (backtick) characters for narrow spaces that’ll be fully removed, and multiple spaces between words where I planned to collapse them into just 1 space. The hyperlinks are made using Inkscape’s Create Anchor functionality.
After exporting the SVG file, it required some post-processing:
In this Reddit thread, user simon1024 shared that they tied fabric from IKEA around the column using a rope. In the photo, you can also see that the clock is held up with a string that goes around the column.
If you are looking to attach fabric to the top of a column, consider using baling wire, Strapping (requires special tools for tensioning and sealing), an Endless Ratchet Tie-Down (doesn’t require tools) or even jumbo Velcro straps. Leave extra fabric at the top of the column, and fold it over the strap to hide it from view.
You can paint the column. Especially if it is bare concrete.
Things get more interested with wallpaper. You can surround it with removable wallpaper or even cover it with vinyl tile wallpaper for an effect like this:
Make sure to test with a small-ish patch to make sure the vinyl tiles are flexible enough to bend around the pillar’s diameter, while sticking firmly. You could also actually tile the column if you’re some sort of Mr. Moneybags 😝
If you own the unit, you can use adhesive to wrap rope all around the column. Use an appropriate adhesive – likely Polyurethane construction adhesive – to glue the rope in place. Consider also threading hooks through the rope. They can serve as points to attach baskets or hanging plants.
Go wild by creating a “Michelin Man” effect around the column by purchasing a lot of Pool Noodles, gluing them around the column and painting. Be sure to test the glue and paint on the pool noodle, because they may contain chemicals that’ll dissolve the noodle.
Pool noodles
You can go further and surround the pillar with flexible “acoustic wall panelling” like this product from MSI Stone:
Finally, you can spice up a plain column by gluing flexible mouldings around the base and top to make it look like an ancient Roman column. Look for a product called “flexible cornice” or “polyurethane moulding”, and make sure it is the flexible variety that can curve to any diameter.
Flexible mouldings from Elite Trimworks
Climbing plants
If you decide to cover the pillar with jute or rope, then you’ll be able to add climbing plants in pots at the bottom. The rope will allow the plant to easily climb up the pillar.
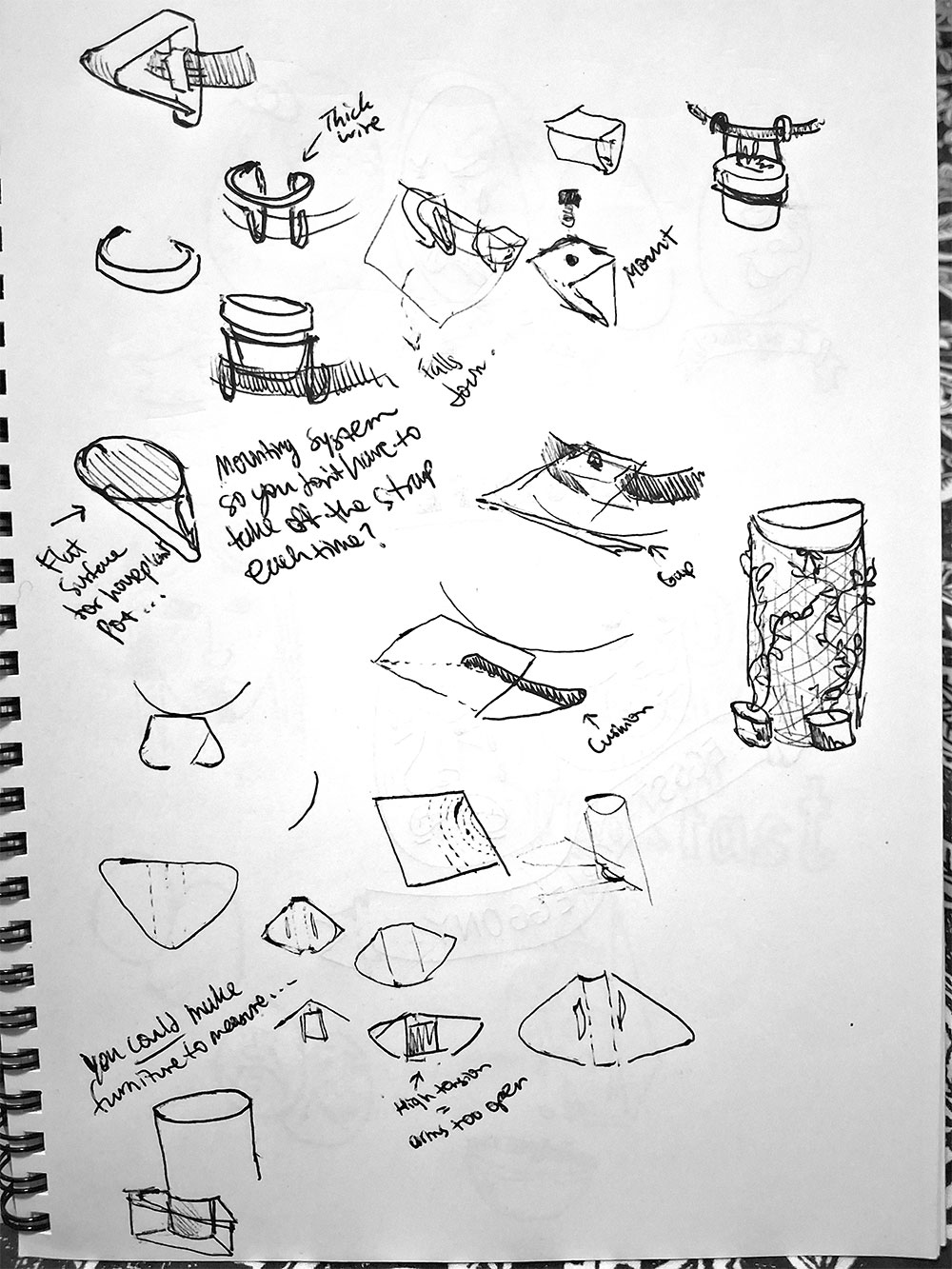
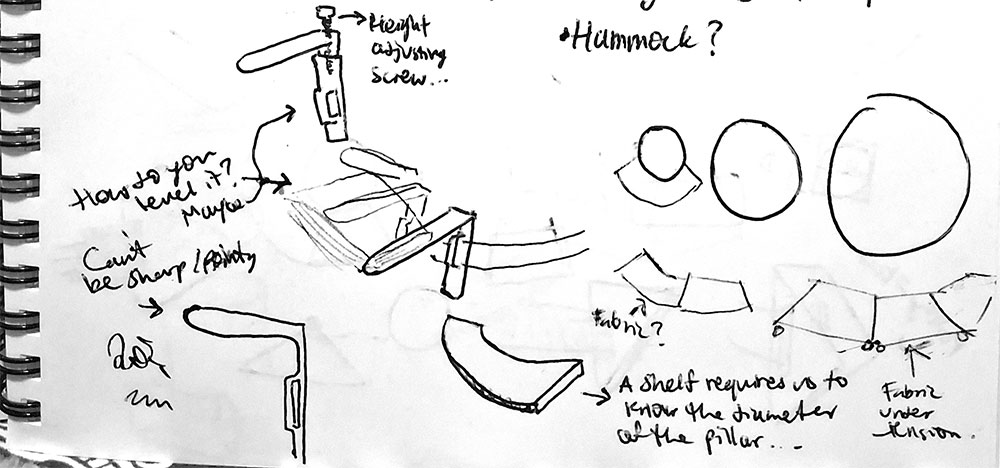
Prop a “shelf ladder” against the column. Think of ways to attach it to the column in a stable way. You may need to use a saw to cut an appropriate-diameter indent in the shelves so that the ladder doesn’t slide off the column’s cylindrical surface.
Depending on the diameter of your pillar, one of these furnishings could fit neatly beside it. You can use them as seating, as a on-level bookshelf, or stack them vertically to create a tall semicircular bookshelf.
Semi-circle table from Boardsdirect.co.uk You can raise the table’s legs by attaching additional pieces and painting the whole thing. This type of seat is called a “tree seat” and there are many products like it available
You can also create a frame that’s suitable for attaching shelves by a children’s “Climbing Arch” sideways. The key is to make sure you have the right diameter for your pillar.
Pikler Climbing ArchGeneric climbing arch on Amazon
Cover it up
You can glue 2″x4″ bits of lumber to the column vertically, which would allow you to drill into the wood and hang pictures, add hooks and lightweight shelves.
You could also fully cover your column with wood up to the ceiling like this:
You could also use plywood panels or acoustic panels.
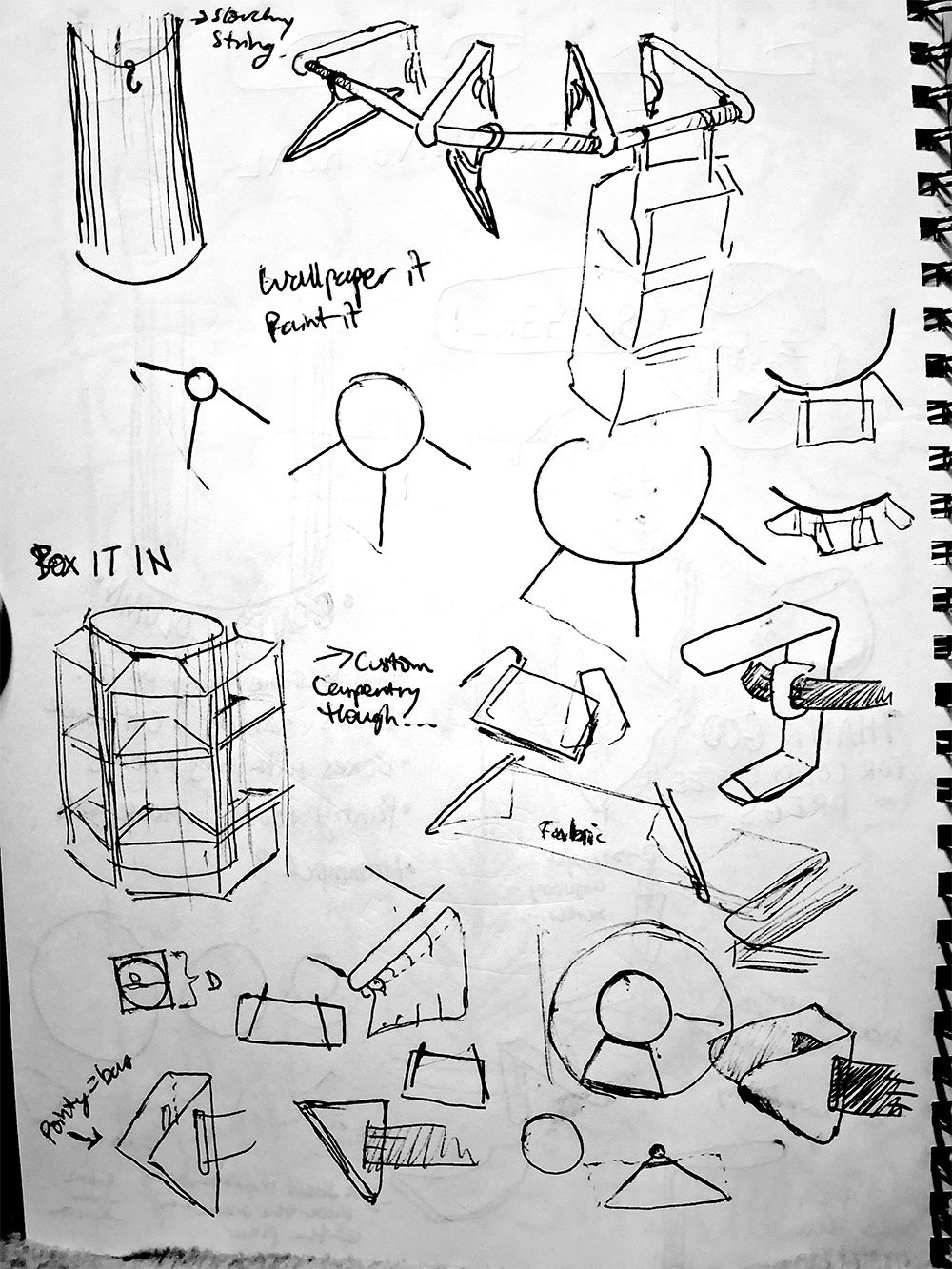
If you “box in” the column completely, with panels that screw into each other on each side, then that could support sturdy bookshelves.
“Straparound” shelves
Use a combination of ratcheted tie-downs and loose shelf supports to create a shelf all around like @thesorrygirls on Instagram did in the linked video.
You don’t have to mess with custom-made semicircular wooden shelves like they did (Mr. Moneypants 🤑). You can install more brackets at waist height an stack books flat on top of them – in that way, the surface of the books will become the bookshelf itself.
For a more basic “straparound” setup, use a Timber Hitch Knot to hang up “sliding kitchen hooks” around your column.
Timber Hitch KnotSliding kitchen hooks
You could also go real deep and design a sort of product prototype around all this 😁:
Note: I don’t have a rounded column in my own home. I’m just shocked at how many of them I see in high-rise units. I’m hoping this page of tips will improve the world by removing a little annoyance from a lot of people’s lives.
Did you know that you’re allowed to make real-world acrylic art that looks like a glitchy Playstation game from the early 00s????
This post will expose you to artists who are doing just that. It started as part of the regular “links post” for July 2026, but got big enough to stand on its own.
Julius Hofmann from Germany makes drawings from a fictional computer game. Many more pictures on his portfolio site (Note: later years’ work gets more adult/explicit).
Yooooo, have you heard of Altın Gün?! It’s a Turkish psychedelic band from the Netherlands.
Last month I heard their music playing at Rooster Coffee House (one of Toronto’s best cafes), and it was so fresh that I’ve been listening to their albums on a loop:
My only previous exposure to Turkish singing has been through the band She Past Away. If a secret little goth heart doth beat under your lace undershirt, then you should be listening to them. It sounds like… if The Cure was a Harkonnen band.
Low-Poly Art
Did you know that you’re allowed to make physical airbrush art that looks like a glitched out Playstation game? I didn’t either!
I wanted to share the art of Sasha Yazov, but found enough similar artists that I got carried away and it became it’s own post for you to check out.
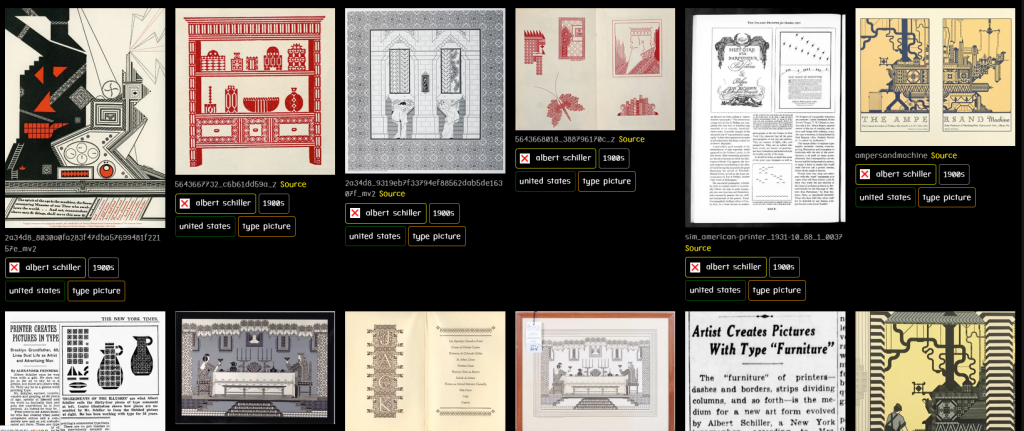
Heikki’s Garden of Flowers made the online rounds in June – it is an exceptional database of typographical art (the moveable-type precursor to ASCII art).
Screenshot of the collected work of just one artist, Albert Schiller
This database is a staggering effort. I am not surprised that it took Heikki 8 years to collect the images he’d made available in that one place. I’ve done something similar, collecting all images related to the Victorian-era Printers International Specimen Exchange, and I’ll tell you that what Heikki’s Garden of Flowers is something really special.
I was particularly impressed by this image from a printer in 1870s Spain that inspired Heikki:
Keep in mind that the above image was composed of hundreds of pieces of lead, all arranged and held together in place under tension with other metal/wooden pieces. Aesthetically outstanding relative to what contemporary (and future!) printers would be doing.
Let’s say that somebody got an all-in-Chinese book about Chinese advertising calendar art from the ~1930s and it’s been on their mind. Here’s a similar book with lots of photos (press the “PDF” button to download).
These posters usually featured attractive ladies, heartwarming domestic scenes, or folktales. Some were really well done:
Trust me, this one exceptional. It has so much dynamism compared to wooden calendar illustrations from that time.
Some of them are delightfully unusual – like ladies playing golf, or this woman out hunting with her dog (remember, this is 1920s-1930s China, not the British countryside!)
Some of the illustrations were hilariously bad:
Oh, darling, what big hands you have!We blame AI art for having messed up hands/arms, but what about the human artists who screw up on this front? What’s going on in the middle there?Ah, the three beauties with identical faces. Very convenient for the artist.
I want to say that calendar advertising is some odd phenomenon from 100 years ago, but then… each year, my family eagerly awaits a pictorial calendar that our local dentists’ office sends out to the neighbourhood. It’s the only bit of advertising they do, and it stands out. Calendar advertising still has a place in modern day marketing!
Cleaners from Venus
Aside from Altin Gun, I’ve been obsessed with the Cleaners From Venus. It is a (mostly) one-man band from the 1980s. Martin Newell seems to be a bit of a cult home-recording and casette publishing hit.
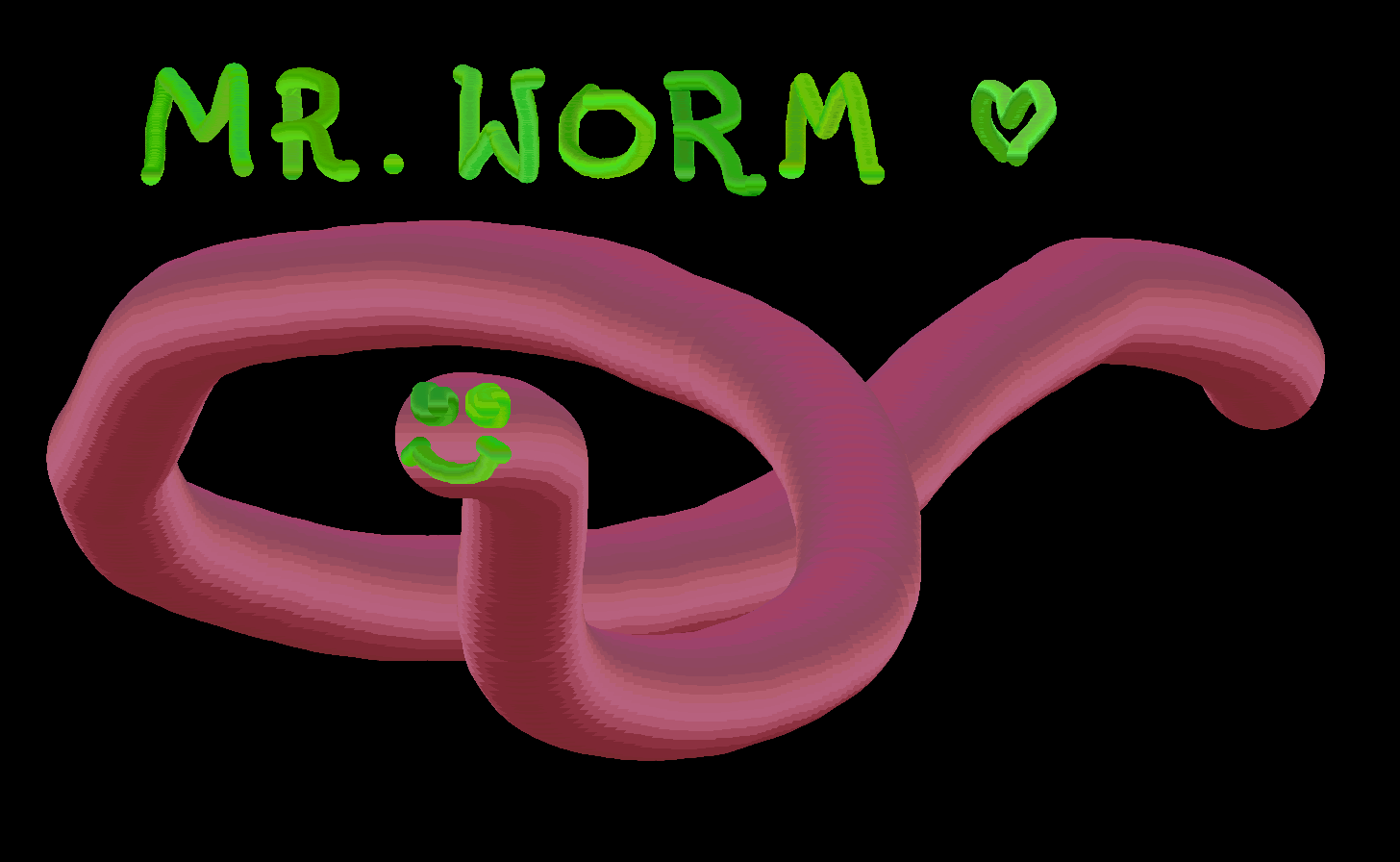
We’ve truly lost the ability to make beautiful computer art like that. All that I – a modern man wunderkind – could manage was Mr. Worm below. (made with HEAVYPAINT):
Baby Limbs
Could I interest you in marble carvings of the limbs of the royal children? The Victorians were truly demented.
I got in this argument with my mother in February:
We live in Toronto. Toronto is a city that does one particular thing very well. It is great at delivering a liminal feeling.
There are vast open spaces in the Northern part. Sometimes, you’ll be waiting for the bus on a cold spring day (no bus shelter! Wind Central!). There will be some geese nearby, nipping at the anaemic grass. And you’ll look up into the big clear sky. And you’ll look down – no people on the street as far as the eye can see. Wow. Wide open.
Sure, there are people in the handful of cars on the road, or inside those middle-of-nowhere office buildings that are becoming economically unviable.
But you’re all alone. And you get that feeling of “nothing is going on here”.
Sometimes I get that feeling when I’m in Toronto’s wonderful ravine system. The city is criscrossed with streams that flow in semi-wild ravines. This setup does double duty as natural sanctuary and flood control system.
You’d listen to the burbling stream. Smell the flowering horse chestnut. Dodge the stinging nettle growing on both sides of the trail. And think, this is nature. I am nature.
And no people anywhere around.
One time, I asked the City, “can you maybe give me other feelings than this liminal vastness?”. Other cities can give excitement, or curiosity, or a feeling of connection with the past. Rome gives beauty – with ornate fountains on every corner, clear cool stream of drinkable water. Montreal gives edginess – groups of young guys, sometimes fighting each other shirts inverted from over the head look at that one go down. London gives hustle – everyone running as rapidly as they can, trying to afford their 10 pound burgers, every little empty nook getting filled through 2000 years of settlement, even in the little dead zones under the bridge someone is running a car mechanic shop.
Toronto just gives liminal.
It’s there on a Saturday in the underground PATH system that links all our downtown skyscrapers. All stores are closed. Just a few human beings clacking their shoes on beautiful echoing granite. 50% of those you’ll meet are security guards. Vast and totally abandoned. You could roll some kids through there on their scooters have a blast (I’ve done it, I know!)
Is it possible to have a city that is all “transit area” with no destinations?
Just endless inbetween, endless road. Flanked by purely logistical amenities for your neverending journey: a Wendy’s to take care of your hunger; Shoppers Drug Mart to get bandaids for your blistered feet; 7-11 to slake your thirst; H&M to buy the next pair of jeans to replace the last disposable pair that disintegrated right on the crotch1.
When I had the argument with my mother she had just moved into the heart of downtown. Oh, how jealous I was! You see, I live in a Midtown neighbourhood that is frozen in the 1950s. Nothing ever happens. All businesses are closed on Mondays. And some, additionally, on Tuesdays.
I told her that she’ll probably have a great time in her new neighbourhood. Imagine, sitting outside at a cafe; people watching!
“Toronto isn’t Paris” was her sour response.
I get it. For years, she’d complained that we don’t have decent opera, quality orchestra performances or museums. That, not only are our cultural activities mediocre, they’re also overpriced. “All people do here is eat at restaurants and go shopping”.
Well, she’s not wrong. It’s hard to find anything that makes Toronto remarkable2. But with an attitude like “It’s not Paris”, you may as well dig a neat little hole in the ground and get all dressed up and buy yourself a nice bouquet of flowers and gently lay down in that hole.
Sometimes you have to invent your own fun. Pretend. Lie to yourself.
Sometimes you have to make your own Paris. Right there in the hallway. In that transit area between life’s loading dock and some temporary storage area from which you can pass into the backstage (before you get on a long escalator to nowhere).
Yes, there are hardly any people in Toronto. Hardly anything to do.
My wife and I are always puzzled when we see a family of German tourists, or a visiting British couple.Why have you come? . “What could there possibly be here for that you haven’t already seen?”, we want to ask.
And yet.
I’d like to think that 2,200 years ago, some weary Gaullish traveller stopped on a mid-river island for a break. “This is neat” he thought to himself. Over there, between the trees, he could imagine a large cathedral. And there, a… a… big king’s palace that will be turned into a museum. And right there on the left, lots of people sitting at little tables, eating some sort of flaky baked good with cups of hot bitter liquid. Oh how wonderful. Magnifique.
And, right there, midway between someplace that mattered and anotherplace important. Right there in the ass-end of nowhere, he decided to make Paris.
As I learned from the book “Ametora“, American lost its capacity to make the kind of denim fabric they had in the 1950s. All the jeans we wear are made of short-length inferior fibres, and that’s why our jeans disintegrate from sitting in an office chair, while great-grandpappy-Filipp’s jeans could survive the grueling work of a gold prospector out West. Japan is currently the place where they have the proper fabric and looms to make sturdy jeans. (Although, just because you see “Japan” on a store, it doesn’t mean that their jeans are hardy – I’m looking at you, Uniqlo) ↩︎
Except, unfortunately, the food is perhaps remarkable. Where else can you tear into sauce-soaked Ethiopian injera, have a deathly-spicy Tibetan tripe dish and drink Vietnamese coffee so friggin dark that I had to ask “where is the condesed milk” and they said “oh, it’s in there” and it just tasted like the deepest darkest chocolate. ↩︎
Once a month my coworkers and I play a game together. This is the story of a game that I worked on for 47 days, a game meant to be played for only 30 minutes at one of those sessions.
My turn to host our team’s online “Social” was on May 28, 2026. Far in advance, I already knew what I wanted them to play. This game was just an idea in my head, but no matter: I figured that I could manually “run the game” by hand using ChatGPT.
My personal philosophy is to first do a thing 100% manually, then semi-automate it, then fully script it. Usually the “manual version” is good enough. So it was settled: I’ll make my game idea come to life as the jankiest manual version of itself.
The game I had in mind
The Dark Lord, and Anubis-looking dude
We are all in a Hell Dimension.
Monsters from all over the galaxy have gathered to battle each other on a desolate planet, under the eyes of a Dark Lord.
Each player picks a noun and their monsters’ image is AI-generated from it. Players are encouraged to choose a silly noun – so you may get a “bubblegum monster” or an “old shoe monster”.
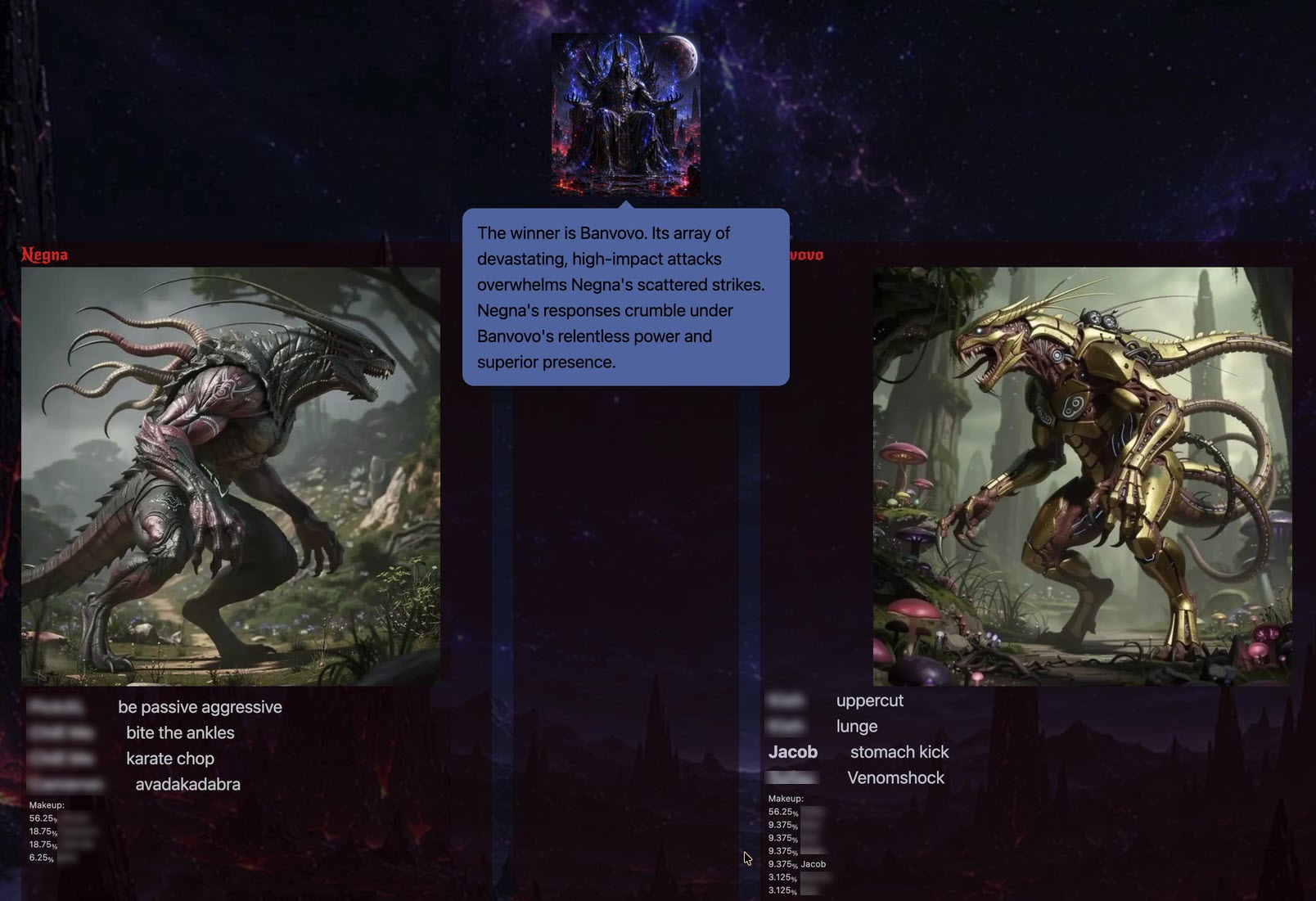
The monsters do battle, with each player typing in attacks as fast as they can for 25 seconds. Finally the Dark Lord (really a ChatGPT adjudicator) looks at the monster’s images and attacks to decide the winner.
Here’s the twist: the winner absorbs the loser.
After the battle, a new monster is created. The new monster is made up of 75% of the Winner’s body and 25% of the Loser. The losing player continues to be part of the new creature. This duo will then fight in a 2-on-2 battle against another duo (with their own composite monster). The “winner’s” attacks are weighed at 75%, but the previous round’s “loser” can still contribute to victory at a 25% weighting. And so on for smaller fractions at future rounds.
The game concludes with an everyone-against-everyone brawl that’ll synthesize the final winner.
Proof of concept
On November 28, 2025, I went ahead and checked if this idea was even feasible. I had ChatGPT do the following:
Generate two monster images,
Decide which one would win in a battle, and
Combine them at a 75/25 ratio into a new monster
The concept looked feasible:
Lobster MonsterCorn Husk MonsterLobster Monster prevails in battle (because its hard shell protects it)
We were in business, baybeeeee!
Are we truly in business, baybeeeee?
I couldn’t think of a way to manually run this experience over a Zoom call. Like, I could collect nouns from roughly 12 teammates, generate initial monsters for them and then what? Make pew-pew noises while they watch me screenshare a ChatGPT session?
I guess I’ll have to build a multiplayer game.
On April 10, I started coding.
Time for tradeoffs
Dear Reader I’ve nevor made a multiplayer game in moy loife.
I’ve only made 1 game before. While it catapulted me to the top of the “violent canal-boat games” category, I built it with the Godot game engine and I had no clue how to use Godot for multiplayer games.
May 28 was fast approaching. The pressure was on, but my work schedule had recently changed in a way that juuust gave me a chance to finish on time.
The fact this game was meant for a specific group of people meant that I could skip certain challenges:
Scaling – only between 10 and 16 people would be playing.
Logins – no need for logins or passwords.
Anti-cheat – this wasn’t some competitive Counter Strike game. Nobody was cheating (and if they were, it would be fugging awesome!)
Sleek design – this game could be real rough, because it’s charm was going to be in the fact that I hand-created it specifically for my coworkers.
Asset hosting – our Team Social will last only 30 minutes, so I didn’t have to worry about storing the monster images. I could just hotlink to the images that my chosen AI platform generates – these image URLs each had an ample 1-hour lifetime.
Funny enough, the unpolished look of the game made it feel like a “quick and simple” creation to me (and I know it was neither!). My programmer sister, immediately picked up on the tonne of work that went into this game, though.
I chose not to vibe-code this thing. Partly because I don’t have experience with coding harnesses. Partly because I wanted to put my own energy into this game so it felt like a gift to others. Finally, I wanted to learn some new technologies and you can’t learn if an LLM is doing all the work for you!
No regrets here. Although there was a tetchy night with just 4 hours of sleep right before the deadline.
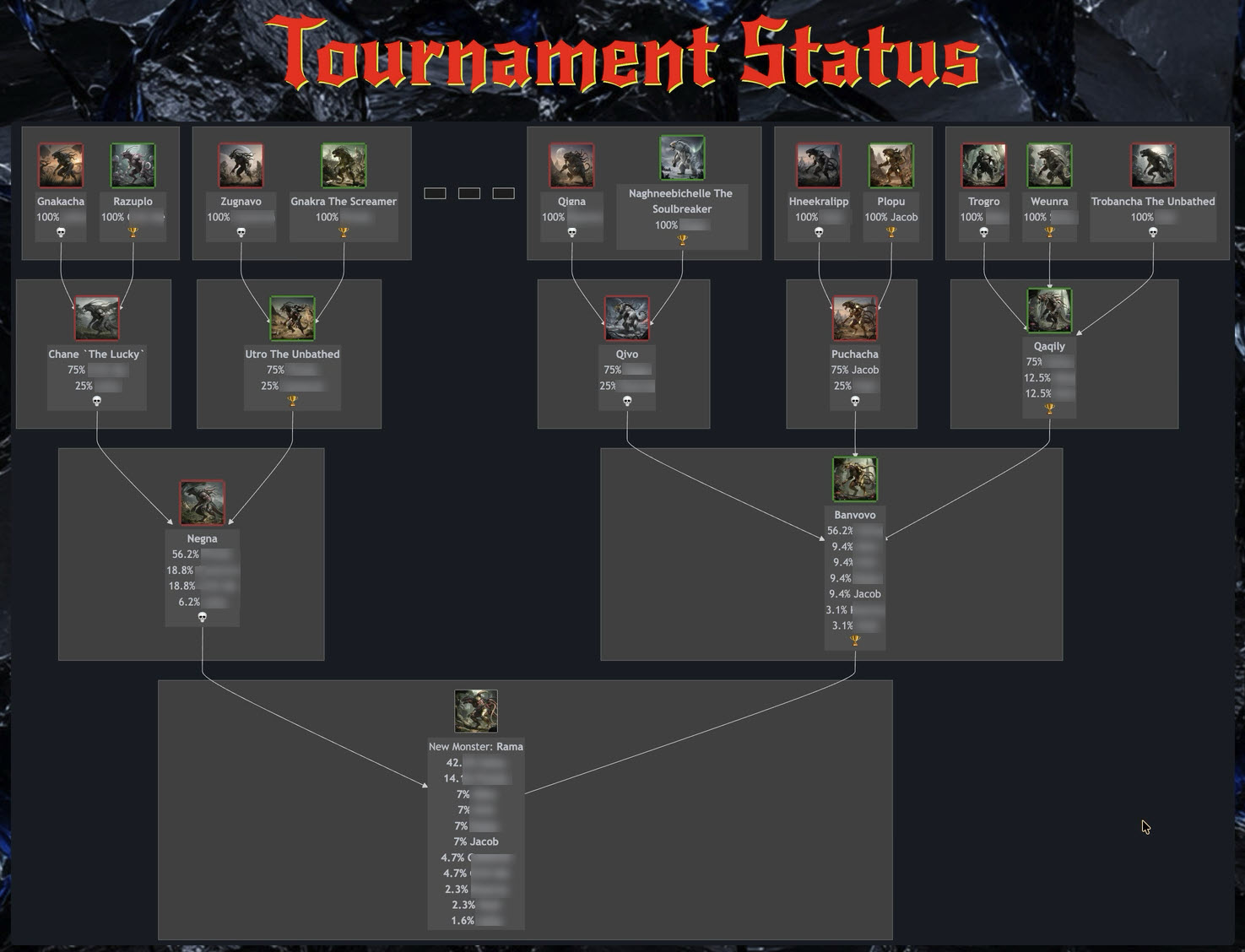
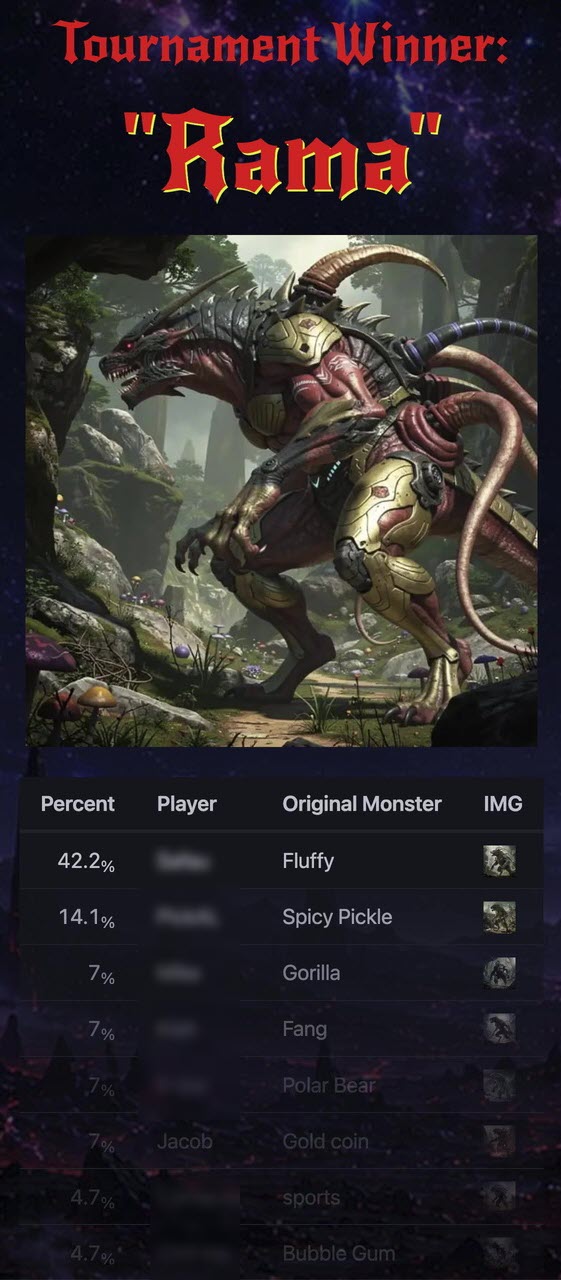
Tournament begins – each monster is made up of 100% one person/nounFinished tournament – the winners absorbed the losers, and synthesized new monsters. Each monster’s composition is shown under its picture.
Me learn little
I’m a strong believer that you should “only have one crisis at a time”.
You could rephrase this as “learn one new thing at a time, while keeping everything else familiar”.
For this project, that meant running the game on my existing – NEARLY UNLIMITED – $90/year shared hosting (affiliate link because I’ve been with them since 2008 and this is what love feels like).
This dictated that I use a “polling” architecture where each player’s computer repeatedly hits the server for updates, instead of a more appropriate WebSockets/Sockets.io approach where the server proactively sends updates to the players only when an update is available.
I also leaned heavily on Python, and SQLite which is my “comfort zone database”.
The 3 new things I decided to learn were:
Building multiplayer capabilities into an app
HTMX: an easy way to do polling, and to make use of data from the game server
Using AI APIs throgh an Inference Platform (I chose Replicate.com)
Hot take: Git is awful version-control software. If it takes everyone a lifetime to understand the mental model of a tool, then it’s been designed very badly. I don’t care how pretty the internals are or that 100 tiny Linuses created it in 1 night while dancing on the head of a pin.
I ended up using “Fossil” version control for the first time. But as an amateur from the “just use CTRL Z as version control” school of programming, I still don’t understand the benefits of it. Finally, I had to learn Mermaid as that was the easiest way to visualize the tournament brackets.
Things that happened along the way
Here are some interesting parts of the 47 day journey:
Everything’s a Chinese Dragon
Initially, I was using “prunaai/z-image-turbo” to quickly generate monster images. But it was really difficult to get the look I wanted. Here’s an example of tweaking the prompt to generate a “crystal goblet monster”:
All the monsters had a particular look. Eventually I thought maybe this image generation model was trained in a way that biases it. Turns out that the Z-Image foundation model was created by Alibaba’s AI division. They must’ve used a lot of images from China during model training, as well as lots of e-commerce imagery. That must be the reason why all the monsters look like Chinese Dragons and/or product hero-shots!
I ended up switching to Flux.2 Pro. That one was created by Black Forest Labs, a German company. Their images more closely matched my concept of a monster. It’s interesting to note that this means my aesthetic preferences have a Western cultural bias.
With all generative image models, I found that some concepts are so strong that they completely override my prompting. As an example, an “owl inspired monster” would strongly snap to being… just an owl:
Attempts to create an owl monster mostly ended up as just an owl. Similarly, some models spotted the word “predatory creature” or “alien being” and would generate monsters that looked identical to the Predator and Alien movie monsters.
I had to put lots of work into the monster-generating prompt. It had to be generic enough to work with any noun, but also consistent enough to give a certain look. This won’t be surprising to anyone who frequently creates AI images, but it was eye-opening to me (or maybe eye re-opening, as I’d previously used Midjourney and all the prompt tweaking was exhausting).
Click to expand the final monster-generation prompt I went with.
A photorealistic fictional predatory alien with a body inspired by {noun} morphology. The creature is 4 meters tall, set in its natural ecosystem on an alien planet where such a creature can evolve. It { random.choice([“has a markedly asymmetrical body”, “has an odd number of limbs”, “has additional tentacles”, “has insectoid antennae”, “has tribal markings on its body”, “has an unsettling look”, “is holding the typical weapon of a ” + noun + ” monster”]) }. Its mouth is open in a snarl.
The design is monstrous, intimidating, biologically plausible. Cinematic wildlife photography style. Facing left.
Here is the typical look of the monsters this prompt generated:
Notice that they’re all bipedal lizardy dudes, framed by the background on boths ides, have the right number of limbs and 5 fingers on their hands. It’s a very standard look and I would use more extreme random elements in the prompt next time (“3 hands”, “a horn coming out of the chest”, “spraying acid”). The look came out a bit vicious. It would’ve been better for a game with coworkers if it was more goofy and lighthearted
How an initial monster looks in the game interface. This one’s a “Gold Coin” monsterAlternative: same “Coffee Monser” from above but rendered in a goofier Pixar style. A bit more work-appropriate.
Adjudication took longer than expected
I thought that, after a battle, deciding on a winner would be quick and my players could read through the decision right away (with the slow work of generating a composite monster image happening in the meantime).
Things worked out the opposite way.
The Dark Lord takes his sweet time to declare a winner
In case of timeout or error, I made the Dark Lord choose a winner at random and say “X wins, because I like the cut of their jib and don’t owe anyone an explanation”. A simple solution for rare errors in a 1-time game!
For some reason, OpenAI’s GPT-5-nano and GPT-5-mini would take 15 – 30 seconds to analyze the monsters’ images and attacks while generating a decision in the Dark Lord’s style. This slowed down gameplay significantly.
In contrast, combining multiple monster images into one only took 13 – 17 seconds. I believe that it’s the analysis of 2 or 3 monster images that slowed down the adjudication. In the end, I chose to use Google’s Gemini-2.5-Flash model for generating the final decisions – it took only 5 – 7 seconds.
Adding some spice
I’ve already listed the things I could remove because this was a game for one group and one time – scalability, authentication, etc.
Towards the very end, I realized that I could add certain in-jokes for the specific individuals playing the game. Each monster had a semi-random name and I made the name sometimes end similarly to a team member’s name. So it would sound eerily familiar but not quite.
Monster name suffixed that would appear 1 out of 25 times
In retrospect, I should’ve made these suffixes a lot more probable. After all, we’re playing this game only once together!
Did my tech choices work out?
With 20/20 hindsight, if I were to build this game again I would’ve upgraded my hosting to a VPS so I could have long-running apps and use Socket.io.
Socket would let the server inform the players when there is a game event / new command to run. I had to build a polling system instead, and that was unnecessarily time consuming. I believe Socket.io would’ve also helped with synchronizing the “current time” between the server and players, to avoid key events like Battle End happening at different times for different people.
I liked HTMX! I never understood the hassle of having the server send JSON objects that then influence the HTML structure of the page. HTMX cuts all that out by having the server respond to REST requests with a finished HTML fragment, that the client then jams into the existing page.
In case you’re curious, the last programming language I actually liked was Perl 5.
I still hate Python but I’ve gotten more comfortable with it because of this project. So, maybe I hate it a little less now?
The final battle: everyone against everyone
Replicate.com was a good tool for testing and switching AI models quickly. Kudos to my sister for educating me about OpenRouter and similar middleware. Replicate made it a breeze to call a variety of AI APIs, a big benefit to the project.
What I didn’t like about Replicate how difficult it was to find a suitable AI model for a given task. Their UI is unusable for this (they provide marketing-speak instead of a comparison of features/speed). I had to use artificialanalysis.ai to choose models for the project. I also didn’t like that Replicate throttles their API usage unless you set up auto-deposits to top up spend. This wasn’t called out upfront and their documentation showed conflicting figures for the amount of preloaded cash that lifts the throttle. Finally, I thought that I’d be able to use one simple API for all models on Replicate, but each one required slightly different parameters and setup. None of these were deal-breakers.
Was the outcome good?
Yes!
The whole team and I played the game and we had fun.
I’m very satisfied with what I built! Visually, the game came out looking very Boris Vallejo (NSFW) / “pulpy” because of the font and the classic hero-stance of the monsters.
The tournament ended and the final monster is born. The player with the “Fluffy” monster is the winner – because their original monster constitutes the biggest portion of this final creature.
The beauty of throwing your life away
Isn’t it funny to spend so much time on creating a 30-minute experience?
On projects like these I am usually torn between two feelings:
As a creative man I often feel like life is slipping away from me. With 2 kids occupying evenings and weekends and a full-time job, I would have to make brutal decisions about how I use my free time. This was especially relevant prior to April, when I’d had only ~2 hours free for projects after the kids went to bed (in practice, this often meant a lack of sleep for me).
But also, I find that these projects – where the effort is comically disproportionate to the output – are the most satisfying to undertake (and read about! obligatory Mehran’s Steakhouse mention). I get to learn something new and, ironically, the noncommercial nature of the project gives me the stamina to carry it out to completion.
Ultimately silly projects like “Monster Mash” are what abundance looks like. They are undertaken out of curiosity and generosity.
If you’ve fallen in love with the Hell Dimension Extended Universe, and you’re a loyal reader of the blog (disloyal readers will be chased out!) then reach out to me and I might set up some games for you & your friends/colleagues. No promises.
As always, I’m <my first name> at <this website>.
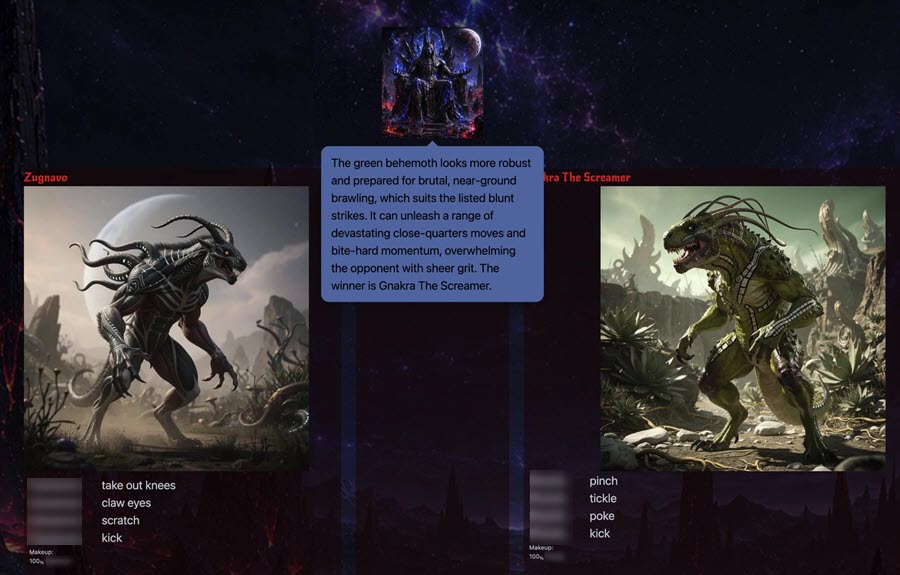
Adjudication for one of the initial 1-on-1 battles.
So, I was reading about the battle of Dien Bien Phu, where the Vietnamese broke the French’s colonial dominance over “Indochina”. And this little detail jumped out:
The French forces came to Điện Biên Phủ accompanied by two bordels mobiles de campagne, (mobile field brothels), served by Algerian and Vietnamese women. When the siege ended, the Viet Minh sent the surviving Vietnamese women for “re-education”.
But of course the French army travels with combat brothels! And they brought two to this battle!
Dien Bien Phu was a whopper of a battle:
The French artillery commander Piroth committed suicide in his dugout by hugging a grenade.
Colonel de Castries effectively checked out and hid in his bunker during the battle. Allegedly leading to a “paratrooper putsch” where another commander took over.
About 50,000 Vietnamese combat personnel fought against 14,000 French.
The battle lasted 55 days – from 13 March – 7 May 1954 (55 days)
Finally, the Viet Minh detonated a 1-tonne explosive mine under the French position on hill A1 and made it disappear:
Reading about the field brothels is a hoot. I especially appreciate that the last one was shut down because of a complaint from a Brazilian pimp about “unfair competition” from the French government. Truly, the wholesome little guy fighting for what’s right.
What’s another year?: The now largely overlooked story of the American civilians that stayed behind in Saigon after April 30, 1975, some due to haplessness, others for heroics, or because they did not want to leave.
The exhortation “learn to code” has its foundations in market value. “Learn to code” is suggested as a way up, a way out. “Learn to code” offers economic leverage, professional transformation. “Learn to code” goes on your resume.
But let’s substitute a different phrase: “learn to cook”. People don’t only learn to cook so they can become chefs. Some do! But many more people learn to cook so they can eat better, or more affordably. Because they want to carry on a tradition. Sometimes they learn because they’re bored! Or even because they enjoy spending time with the person who’s teaching them.
Weird device: the Cuttelola Dotspen – the motorized pen that puts down dots for you!
That’s it for now – if you liked one of these links, share it with your friends!
Remember: Facebook, Instagram, Linkedin and Twitter intentionally hide links that you share on their platform. Because they hate the Web. Each link you share is a little bit of spit in their eye. A tiny likkle spittle for our beautiful friend Mark.
Every year, I try to visit my local “Arts College” – OCADU – to see what creative young people are up to.
This post is the first time I’m highlighting the people who’s work made an impact on me, to give them some publicity. Go ahead and visit their sites:
I really liked Selina Zheng‘s “Shanzhai Is Culture” graphic design capstone project. She made a neat zine that explained how bootlegs and fakes are not considered “bad” in Eastern cultures, and she showed appreciation for the fun and creativity of knockoffs. Selina was inspired by Pacific Mall, which happens to be one of my favourite places in the Greater Toronto Area!
Also in Graphic Design, Warrick Bruan (a friend of the blog commented that he has a fantastic name) his photography of decaying signage and the patina of age that certain materials gather when they’re used on building facades. He developed the photos in OCADU’s darkroom, and created 3 small books themed on metal, masonry and wood. He also created a 3D-printed building that is made up of liminal spaces (and continues in an infinite loop if you look at it just right).
There were several strong photographers at GradEx 2026, with 2 or 3 strong “absurd” photographers’ work exhibited together in a small room to great effect. Interiors by Reilly Narod. Blue 52 by Ethan Yoshitomo. And a third series of photographs of used up soap/items.
Maya Jurichad a series of large prints called “When I’m in Cosplay”. The prints themselves were intentionally faded/processed and featured her friends in Cosplay. What I liked about these photographs is that they reflected her love for her friends and showed everyone in their best light – similar to the qualities in a John Singer Sargent portrait. (A certain friend of the blog pointed out that, while I thought of Sargent showing women “as they are”, I was mistaken. Their necks and limbs are unnaturally elongated. Touche.)
Finally, Ilaria Serra had these great ethereal 80s photographs in her “Liminal Reflections” series. I even bought a couple of small prints!
In the Illustration program, Kaisy Tsoi was hands-down the standout star. Her series of soft illustrations commemorated pets who passed away – and their special quirks. I think what’s interesting about Kaisy is that she has her own style and has something to say (sort of like the embroidery in Tomoko Konoike’s project that delivers a brutal message in a cutesy package).
The vast majority of the young illustrators at the show had strong technical skill – but they’re young and don’t have a strong message to deliver. Yet.
Lin Sun’s unique creature illustrations stood out. There’s something original here – Lin knows how to elongate and twist a body while keeping the end result cohesive.
Ren (https://imginn.com/shadow.elysium/) had several illustrations themed around death and warfare. This one contrasts the glamour of war with the fact that the warriors are disposable cogs in the machine. I like the layout.
Edouard Vallerand (https://imginn.com/lazy_cr0w/) presented a collection of illustrations from a post-apocalyptic world. We definitely have a kindred vibe and I appreciated his entertaining takes on futuristic cults, like these “Harbingers of the Invisible Gifts”:
This cult worships the power of nuclear waste and the mutations and afflictions they provide from the invisible radioactive gifts that are given by their entity, The Kind One. They congregate in old, worn down nuclear facilities where the people of the old time have set up large spike monuments to worship their deity.
Devin Yang‘s work stood out from the other illustrators’ in the large hall. It is vibrant and dynamic. His style is not my jam, but I gotta give kudos to the lively spark in his work. His website his here.
Daniel Vrbos made a font by running an ink-dipped marble in a series of rubberband tracks that he constructed. The result was pleasing and “punk”. Daniel’s site is at danielvrbos-portfolio.format.com
Daniel has several interesting ideas on his site – like graphic design work he’d created with unusual tools (ie. no Adobe tools!):
Aaryan Pashine had several cool books laid out. Aaryan creates custom programs that generate bespoke book layouts. He also makes generative images. And an XKCD search engine that reveals all the traffic going back and forth between the client and server as you do the search…. Just wild stuff. Check out his site a-p.space.
In the Painting department, I liked this “centauress” by Maya Kaplan. The rest of the collection is also wonderfully weird. Like melonking in real life.
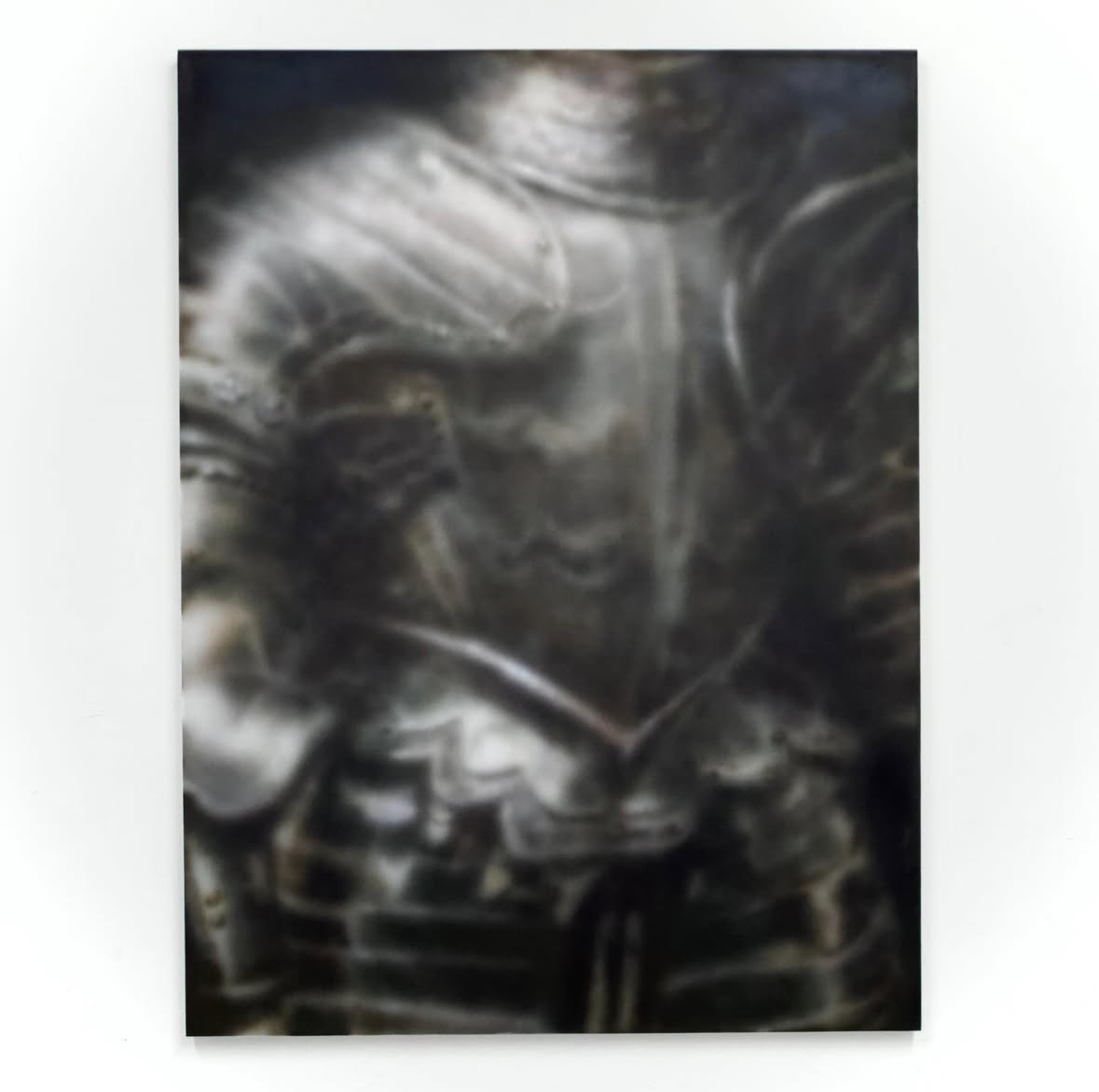
Jake Santos (https://imginn.com/jaeksantos/) had a series of 4 defocused airbrush paintings of European metalwork. The paintings are large, so they create a very odd feeling when you stand nearby – something almost recognizable but not quite. Like you’re stroking out.
They’re usually depicted with heavyweight rifles and babies. And they’re definitely not wearing those impractical “battle bikinis” in the Yank illustration.
Looking at the artwork above reminded me of this beautiful staged propaganda photo of a “field hospital”, from the later war against the USA:
Hah! “Saigon Sally” is probably a stand-in for “Hanoi Hannah” – a real Vietnamese broadcaster who’d try and demoralize American soldiers with her English-language broadcasts. She’d play music, read listener-submitted mail, list the names of freshly captured US soldiers and announce the locations of American units.
Eastern Jewel
The “Related Articles” list for Hanoi Hannah is wild. Including Eastern Jewel, a transgender spy for Manchukuo (sorry to burst your kawaii bubble!) who was descended from Japanese royalty.
“Will ya just stop asking what I’m thinking about?! I’m not thinking about anything!!!” sourceWhat was the rhyme from Basic Training? “Two in the head / make the shark dead” source
https://archityp.es – great storefront typography from the streets of France.
So, there’s this 4-volume book with photographs of China from 1873 (!). The couple above are getting married, and the photographer just goes savage on Chinese marriages:
Dreary and uninteresting from beginning to end is a Chinese marriage ceremony and in too many cases it must lead to a lifetime of disappointment and tears. In China, as in other parts of the world ladies prefer if they can, to get a glimpse of their intended partners. This may be done if circumstances are favourable but frequently they never see their lord and master, until the day when they are united to him for ever. One can readily fancy that, at such times, the first sight of an ill-favoured face will create a sad feeling of disgust and disappointment.
This post is not a review – it’s just a page about my favourite prepackaged coffee. I like drinking this Coco Bruni Americano coffee pouch. It is available here in Toronto at the “Galleria” Korean grocery chain.
When it disappeared from the store, I couldn’t find it again because I didn’t know the brand. Now that it is back, I’ve created this post as a way for others to find this brand through general search phrases.
The phrases I most associate with it:
Girl on a bird coffee
Girl riding a bird coffee pouch
Korean coffee pouch drink
Coco Bruni coffee
The design of these pouches is really something. There is an inflated handle for you to comfortable hold it. You can tear off the tip and pour the coffee into a cup, or you could use the telescoping straw to drink this like an adult juice pouch.
These Coco Bruni pouches seem to be associated with a fancy cafe based in Seoul, South Korea:






































































































































{kind=link}