Recently Jacques Corby-Tuech, a Marketing Technologist with skills and attitudes similar to my own, wrote a post about how Marketers are addicted to bad data (archive link).
Jacques showed some great examples where marketing data is seen as reliable – but is actually broken. Even the processes used for decision making around marketing data are often broken (ex: split tests and statistical significance)
Because I’m passionate about the topic of marketing data, I’d like to add 2 types of Bad Data to the original list and offer 7 tips for marketers to stay productive despite this issue:
Your ad dashboard is tainted by fraud
Jacques touches on the issue of ad fraud – especially when it comes to ad exchanges.
On an exchange, you don’t really control which websites your ads show up on. There are publishers who generate fraudulent traffic and clicks to steal part of your ad spend.
This was a major problem 10+ years ago when I was an affiliate advertiser buying display ads and when I became pricing analyst at a digital ad network (hello to my Olive Media peeps!).
Since then, the problem hasn’t been solved at all.
As a digital advertiser, part of your budget is absolutely being siphoned off by fraud.
One way in which you could try to control fraud is to advertise on an ad network that also owns the properties on which the ads run. These are the big ad networks: Google, Twitter, Linkedin and Facebook. Essentially, there is a lot less fraud on Facebook because the company has full visibility into the kind of content and usage that happens on the website facebook.com.
Unfortunately, if you think that advertising on Facebook will protect you from fraud then you are mistaken.
Back in 2014, the Youtube channel Veritasium showed that there is a lot of ad fraud on Facebook and how it happens.
Question: Why would someone run a network of bots to click on Facebook ads, when they’re not even collecting a portion of the ad spend?
Answer: Because such clicks make their account look more like the activity of a real person to the Facebook algorithm. The people who run these fake accounts can then sell the account, or use it to “Like” the webpages of businesses who purchased fake likes.
Why does Facebook allow this activity to go on? Because fake likes increase the revenue they collect from advertisers. Publishers, ad networks and agencies have a financial incentive to ignore fraud. Only the advertiser cares about fraud, because everyone else makes money off of it.
You don’t know where your money goes
Another problem – completely separate from fraud – is that the digital advertising ecosystem is opaque. You won’t be able to discover where your money goes, and you won’t be able to control where your ads show up.
That last point is crucial for brand advertisers. This concept is called “brand safety” – can an advertiser ensure that their ads don’t show up next to an Al Qaeda videos? (2017)
In 2018, this was such a problem for Unilever CMO Keith Weed that he publicly threatened to pull ad spend from Facebook and Google, unless these publishers crack down on extremist, divisive content.
CMO Weed talks about the digital supply chain being “at times is little better than a swamp in terms of its transparency”.
Wrap your head around this: a massive advertiser like Unilever can’t control where their ads show up in a fully owned + controlled platform like Facebook. If Unilever doesn’t have the ability to control what content their ads are served besides, then you don’t stand a chance.
How would you know that your campaign is being shown to your relevant audience?
Here is a more recent example of the same problem. This time in the Wild West of programmatic advertising – a very complex marketplace that is not fully owned-and-operated like Google or Facebook properties.

In May of 2020 the ISBA – an organization representing the UK’s advertisers – reported on an ambitious audit to find out where advertiser money ends up when you purchase digital ads on an exchange. Participating advertisers included BT, Nestle, Unilever and Tesco.
They found that – not looking at fraud – 15% of all ad spend couldn’t be accounted for. It disappears somewhere between the advertiser and the publisher. And this is when everyone is being cooperative and transparent.
The executive summary of the report presents a few potential places where the data becomes wonky:
The unknown delta of 15% represents around one-third of supply chain costs. Even in disclosed programmatic models, this amount remains unattributable.
The unknown delta could reflect a combination of: limitations in data sets, necessitating occasional estimations; DSP or SSP fees that aren’t visible in the study data; post-auction bid shading; post-auction financing arrangements or other trading deals; foreign exchange translations; inventory reselling between tech vendors; or other unknown factors
ISBA Programmatic supply chain transparency study, May 2020
If you purchase programmatic ads, then at least 15% of your figures are incorrect.
Making sure that bad data doesn’t bite you
Right now, Jacques doesn’t know what the way out of this mess is.
From my end, here are some practical approaches for lowering the impact of bad data that I use with Marketing Teams:
Tip 1: Every ad platform has a catch
In my experience, every ad platform has at least 1 big “catch”. This is a default setting that will cause advertisers to overspend.
- At Google Ads, here are some of the sketchy things they do:
- Google Ad Suggestions – Google will auto-generate and approve ads on your behalf, unless you actively opt out. I don’t have any idea of how effective this auto-generated ad copy is for advertisers, but I’m sure it increases spend on Google Ads.
- Google Merchant Ads, ads that are auto-generated from e-commerce product feeds, sometimes target nonsensically broad keywords. For the LexisNexis legal bookstore, Google automatically ran our ads on keywords like “Amazon” and “Canadian Tire” (a popular Canadian hardware + home goods store). This was an absolute waste of money that required proactive action to stop.
- The default bid type is “maximize clicks” for your budget. This asks the advertiser to give Google free reign to try and use up the entire budget – with no upper limit set to control the ROI/Return on Ad Spend

- Twitter
- By default, you can run a campaign without any type of targeting. If memory serves me right, Twitter’s default targeting is overly broad.
- By default, you can run a campaign without any type of targeting. If memory serves me right, Twitter’s default targeting is overly broad.
- Facebook
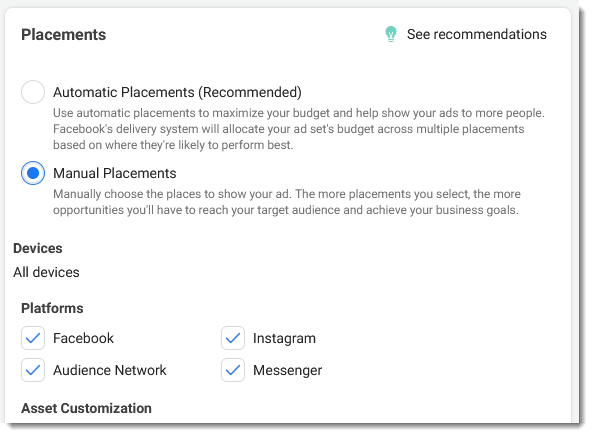
- Automatic placements – by default, Facebook sets up your ads to run automatically across their entire network. This is probably not something you want. When you click through to set up placements manually, you can see that your ads would’ve run across Facebook and Instagram, and Messenger, and the 3rd party website network. What’s the chance that 1 ad creative will work well across 4 completely different experiences?
- The other catch appears to be around ad delivery pacing and billing/bidding options. The campaign objective you select at the very beginning of your setup locks you into a set of options that you can’t change freely. You’ll have to do a lot of research and set up the correct campaign objective upfront.
- Automatic placements – by default, Facebook sets up your ads to run automatically across their entire network. This is probably not something you want. When you click through to set up placements manually, you can see that your ads would’ve run across Facebook and Instagram, and Messenger, and the 3rd party website network. What’s the chance that 1 ad creative will work well across 4 completely different experiences?
- Linkedin
- Linkedin Audience Network – by default, your ads will be opted in to appear on websites and mobile apps other than Linkedin. Which sites? Who knows?
Keep in mind that, although you are targeting the same Linkedin users, you may not want your ads to show on 3rd party sites. For example, if your closely tailored your ads’ visuals and copy to appear in the Linkedin feed. In that case, if your ads show on an another website, they won’t make sense.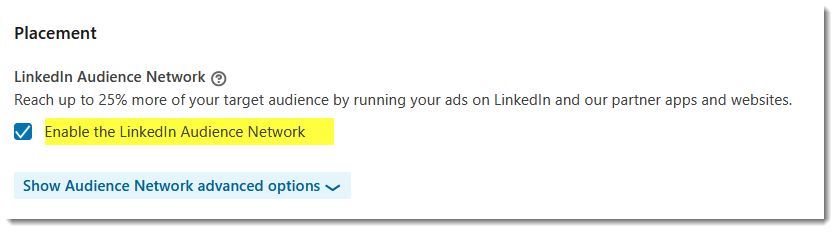
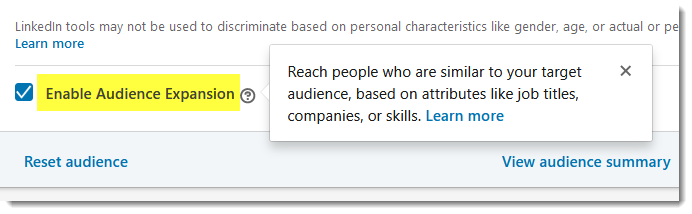
- Audience Expansion – this is another setting that’s enabled for your campaign by default. It is “lookalike” targeting that shows your ads to people who are similar to your target audience, but who are outside of the campaign parameters you specified. You run into issues where, for example, you are trying to sell a product to Accountants who work at large firms. But your ads end up also “expanding” to target Accountants who work alone – an audience that you didn’t want to target.
- Linkedin Audience Network – by default, your ads will be opted in to appear on websites and mobile apps other than Linkedin. Which sites? Who knows?
The key point for Marketers is that there is always a catch when setting up an ad campaign. Look for it. If you can’t find a default campaign setting that puts you at a disadvantage, then you aren’t looking hard enough.
Tip 2: Split testing is a lot harder than you think
If you’ve worked with me, you probably noticed that I’m not excited about A/B testing – despite being very data-focused in other ways.
That’s because most marketers miss a critical fact about split testing: you need a lot of conversions in order to make statistically-valid conclusions from your test. One rough rule of thumb is that you need 100 conversions on each variation.
That has 2 key implications for split testing:
You need lots of conversions to run effective tests
To gather enough data to make valid conclusions, you need to be in an industry where there are a lot of customers and the sales cycles are fast. This way, you get lots of opportunities to gather data and learn every month.
Realistically, if you sell directly to consumers (B2C) or if your clients are small owner-operated businesses (B2B – like restaurants, dental practices, solo lawyers) then split testing is a good tool for you.
If you sell to a small base of customers, or the sales cycles are long, it might take you an entire year to gather enough data for just 1 valid test. Don’t worry about split testing if that’s your situation. Rely instead on surveys and learn by talking with your customers.
You can always go up the funnel to get significant volume
If you have few sales each month, but still want to make use of split testing then think about going “up the sales funnel”.
Instead of split testing a sales proposition on your landing page (which one got more form submissions?), you can get more data by split testing the same proposition on your display ads (which one got more clicks?)
A test’s purpose is to learn about your customer
Many marketers view split testing as a checkbox. This is another “dirty data” activity where we’re generating numbers that look fancy, but we’re not getting any value from it.
“We’re doing split testing”. Great. We’re on the cutting edge.
But this is forgetting the real purpose of split testing: learning about your customer.
Every split test should result in a learning that you can apply across multiple marketing campaigns. If you are testing email phrasing variations for the sake of just having different wording, then you are doing it wrong. You should have a thesis about what your prospects value – and then you should test phrasing variations as a way to prove whether your idea is correct.
Remember: if you are using split testing to decide among 41 different shades of blue. You are doing it wrong.
Tip 3: You can live with bad data if you document your process.
This is an approach I use for important monthly reports that combine data from many sources.
Your data might be dirty, unreliable, or even the wrong data to use for the purpose at hand. But you can still get value from it by documenting some key aspects of the reporting & analysis process.
I recommend that you write down:
- Where the initial numbers came from, and step-by-step instructions for pulling them down.
- The context and assumptions around each piece of data.
- Weaknesses with the current approach and opportunities for improvement.
- Write down concrete examples of weaknesses, so that a decision-maker without full understanding of the data can still understand the implications of the problems you’re describing.
The data you got, and your analysis of it, might be flawed right now. But with enough context around needs, assumptions and weaknesses, you’ve given someone in the future enough tools to make it better.
Tip 4: Get the right data, not the “right now” data
When we look at the bigger picture, one core problem with data in marketing is that marketers tend to use the data they have rather than the data they need.
What do I mean by that?
When you structure your marketing activities around maximizing clickthroughs / ad views / visits / Net Promoter Score just because you have easy access to the figures, you open yourself up to all the risks of bad data.
The alternative is to come up with a strategy and figure out what data you need as part of the strategy. This data may not exist – you might have to invent a process for capturing it, or use some sort of “good enough” proxy.
Tip 5: data resolves disagreements about reality
The book “Playing to Win” by A.G. Lafley, and Roger L. Martin has a great tip for using data in strategic planning. The authors explain that disagreements about a strategy often arise from different people having different assumptions about reality.
Tasha wants to boost sales by offering a discount (she’s assuming customers are price sensitive). Alice wants to boost them by providing a money-back guarantee (she’s assuming customers are risk averse). Each strategy is correct in it’s own world where Tasha and Alice’s assumptions are correct. Tasha and Alice are, at bottom, disagreeing about the reality on the ground.
In those kinds of conflict, Martin and Lafley tell us to use data to break the impasse: we should call out the assumptions of the disagreeing parties. And then collect real-world data that will show us who’s right.
In a real world setting, you would often say something like: “If Tasha is right, then I expect to find data that shows XYZ”. And then you’d look at the data to see how it looks.
Tip 6: Question “just so” stories you tell yourself
Once we are aware of the weaknesses of marketing data, and are intentional about collecting the data we need, I think we get to an even bigger issue: “just so” storytelling with data.
Often, I find that teams make a decision and then look for data that confirms that decision. And then stop.
What I try to do is to keep looking at data after I’ve proven my point. I keep looking for data that disproves my point.
You’ve found data that supports your views. Great.
Now think: what other scenario could’ve generated similar looking data? Is there a second batch of data that that this unexpected scenario also generates – so that I can confirm?
For example, you might be running an e-commerce site that gets a traffic spike on the first week of “back to school” each year. You think that this is due to parents having a lot of time to shop, now that they’re back from holidays and their kids are at school. But another scenario is that university students – the students themselves – are shopping on your site. In that case, you need to dig in to the purchase data to see what kind of products are being bought etc. to tell the difference.
You don’t need to second guess yourself all the time. Challenge yourself to think of just 1 alternative explanation to the data you’re seeing.
Applied on a larger scale of an entire Marketing Team, you could apply these ideas by designating a “Devil’s Advocate”. A person who:
- Writes down what assumptions your team’s decisions are based on
- Proactively asks: what if these assumptions are wrong? What kind of data would we expect to see in those cases?
- Asks “what other phenomenon could explain the data you are seeing”?
- Seeks out risks (“If you can’t think of three things that might go wrong with your plans, then there’s something wrong with your thinking.” – Gerald Weinberg)
- Kickstarts the process of finding data to prove/disprove the assumptions made above.
These kinds of roles already exist in cutting-edge teams. Check out the concept of “Designated Dissenter” in Episode 175 of the Greater than Code Podcast.
Thank you for reading.
Please add your thoughts below, or write your own response post and let me know about it!
