Интернет
Поиск русскоязычных материалов в Интернете
Вадим Степанов
Сверхбыстрый рост объемов информации сделал русскоязычную часть Интернета трудно обозримым океаном разнообразнейших сведений. Очень скоро обозначилась необходимость создания специальных средств, позволяющих легко ориентироваться в ресурсах глобальных сетей.
Сегодня серьезное отношение к работе в Интернете предполагает переход от принципа «найти хоть что-нибудь» к правилу «найти все, что есть». Вернее – все, что представляет интерес по данной теме. В этих обстоятельствах списки узлов по определенной тематике, всевозможные «желтые страницы» или карты Web-серверов уже не могут дать исчерпывающих сведений. Ситуация в киберпространстве меняется столь быстро, что все эти данные серьезно устаревают уже в момент своего появления на свет. К тому же, поддерживать подобные перечни в актуальном состоянии становится все труднее из-за обвального роста новых и новых узлов.
Оптимальным решением в этих условиях является обращение к специальным поисковым средствам (search engines), задача которых как раз и заключается в выявлении нужных сведений.
Принцип действия всех поисковых средств аналогичен работе традиционных баз данных, когда в ответ на ввод в поисковую строку ключевого слова выдается перечень документов, содержащих искомое понятие. Такие системы, по существу, являют собой базы данных слов, полученных при периодическом сканировании виртуального информационного пространства. С помощью специальных компьютерных программ-роботов поисковые средства регулярно обследуют Интернет (главным образом World Wide Web и Usenet), фиксируя все существующие, в том числе новые и обновленные, ресурсы и удаляя сведения о вышедших из употребления. Этот колоссальны и материал, с указанием ссылок на то, где хранится каждое слово, содержится в виде гигантских индексных файлов, к которым и происходит обращение при конкретном запросе.
Достоинства и недостатки поисковых систем складываются из нескольких важнейших характеристик. Принципиальным является то, насколько полно та или иная система обследует документы, то есть все ли слова заносятся в индексные файлы или же только термины из названий, заголовков, резюме, первых нескольких строк или страниц текста, и т.д. Важно, как часто происходит обновление данных, каким образом системы «взвешивают» понятия, определяя степень их соответствия данному запросу. Не последнюю роль играет простота и удобство интерфейса, возможность использовать логические операторы и операторы расстояния, а также дополнительные сервисные функции.
Работа с поисковыми средствами зачастую требует от пользователя определенного опыта и серьезных навыков, поскольку простой ввод искомого термина в поисковую строку может привести к получению в ответ списка из сотен тысяч документов, содержащих данное понятие.
Для поиска русскоязычных материалов среди доброй сотни поисковых систем стоит предпочесть несколько наиболее признанных, позволяющих выявлять информацию с высокой степенью полноты и надежности. Естественно будет разделить их на зарубежные и отечественные разработки. Среди первой группы к таковым относятся AltaVista (http://www.altavista.digital.com), HotBot (http://www.hotbot.com), InfoSeek Ultra (http://ultra.infoseek.com), Lycos (http://www.lycos.com), WebCrawler (http://www. webcrawler.com) и MetaCrawler (http://www.metacrawler.com). Среди отечественных выделяются Stack Rambler (http://www.rambler.ru), «Новый русский поиск» (http://www.openweb.ru/koi8/cgi-bin) и «Паук» (http://spider.raser.ru).
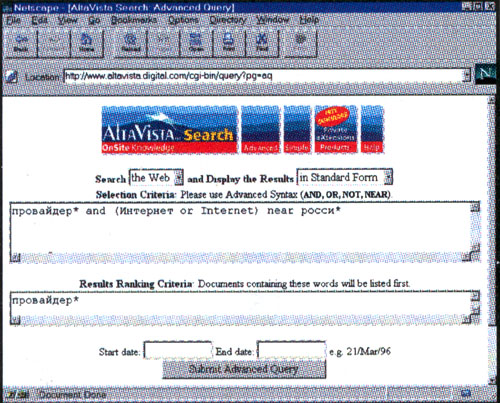
К числу наиболее известных принадлежит AltaVista, мощнейший аппаратный и программный потенциал которой позволяет проводить поиск по любому слову из текста Web-страницы или статьи в телеконференции. AltaVista содержит сведения о более чем 30 миллионах Web-страниц и статьях из 14 тысяч телеконференций. Эта система использует самый обширный и, наверное, самый сложный механизм составления запроса. Он включает комбинации отдельных слов, словосочетаний и знаков пунктуации: кавычек, точки с запятой, двоеточия, скобок, плюса и минуса, а также булевых операторов AND (и), OR (или), NOT (не) и NEAR (рядом с), – последние в рамках углубленного поиска (advanced search). Их сочетание позволяет наиболее точно составить поисковое предписание. Так, знак плюс, стоящий перед словом, означает, что этот термин обязательно должен присутствовать в документе; знак минус – наоборот, отсеивает все материалы, содержащие это понятие. AltaVista допускает поиск по целой фразе (в этом случае все словосочетание заключается в кавычки), а также поиске усечением окончаний, для чего в конце слова ставится «*»(звездочка). В частности, для получения сведений обо всех русскоязычных материалах, имеющих отношение к телекоммуникациям, достаточно ввести «телекоммуникац*». Поиск же данных по теме «российские провайдеры Интернета» предполагает более усложненный вариант «углубленного» запроса: [провайдер* and (Интернет or Internet) near росси*].
Система чувствительна к употреблению заглавных и строчных букв. При использовании заглавных букв она ищет только термины, начинающиеся или состоящие из заглавных букв; при вводе строчных знаков система выявит все соответствующие термины. Пользователям предоставлена возможность ограничивать поиск отдельными фрагментами Web-страницы: заглавием (title), электронным адресом (url), основным текстом (body). Так, запрос вида [titli:виртуальн*+реальност*] выявит все материалы, в заглавии которых присутствует понятие «виртуальная реальность», независимо от употребленных падежей и склонений русского языка. При углубленном поиске можно ограничить поиск также по дате последнего обновления искомых документов. С недавнего времени поиск в AltaVista можно осуществлять, используя интерфейс и, главное, морфологические возможности отечественной системы flndex (http://www.cti.ru/alta.html).
Появившаяся осенью 1996 года система Ultra InfoSeek несколько напоминает AltaVista, однако объем обследуемых ею полных текстов документов уже превышает 50 миллионов Webстраниц. Представленная бета-версия дает основание заключить, что Ultra InfoSeek действительно довольно мощная система, производительная и простая в обращении. Методы составления запроса почти такие же, как и в AltaVista, но все же не столь богатые. При почти полном сохранении значений знаков плюса, минуса и кавычек, чувствительности к разнице заглавных и строчных букв, а также возможности ограничивать поиск фрагментами Web-страниц, – Ultra InfoSeek пока не способна определять рядом стоящие термины (нет оператора NEAR), ограничивать поиск по дате обновления источника и, главное, усекать окончания ключевых терминов.
Как бы в компенсацию, данная поисковая система содержит массу факультативных функций. К таковым относится, например, возможность определять количество ссылок во всей WWW на конкретную страницу (то есть, насколько она популярна) или же, наоборот, выяснять, сколько ссылок на внешние страницы содержится на данном узле (вернее, сколько из них отражено в индексных файлах InfoSeek Ultra). Кроме того, при добавлении нового адреса (функция Add URL) заявленные страницы становятся доступны для поиска немедленно.
Лидером по числу обследуемых Web-страниц (более 68 миллионов) является поисковая система Lycos. Ее идеология формировалась несколько лет назад и была ориентирована на иные аппаратно-программные возможности, поэтому она обладает более скромным набором поисковых команд. В ее арсенале знак«-»(минус), выставляемый непосредственно перед термином, появление которого должно быть исключено; точка после слова, которое должно быть употреблено только в указанном виде (запрос «журнал.» отсеет «журналы» или «журнальный»), и, наоборот, знак «$» – для нахождения указанного корня слова с какими угодно окончаниями (запрос «компьютер$» выявит «компьютеры», «компьютеризация» и прочие производные). Lycos допускает ввод до семи терминов, но не приветствует употребление в запросе символов и чисел (типа «с++»). Выдаваемый системой результат поиска содержит самый информативный реферат найденных страниц. Щелкнув по надписи «Customize search», пользователь может получить доступ к более удобному поисковому интерфейсу, который, однако, принципиально не расширяет поискового потенциала системы. Ординарные интеллектуальные способности возмещаются заслуженной славой справочника Lycos, по праву считающегося одним из лучших в Интернете, и дополнительными функциями, такими как поиск сведений об отдельных лицах, интерактивные географические карты, и т. д.
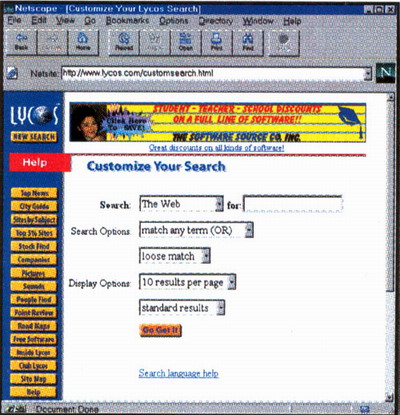
К ряду самых мощных поисковых средств в World Wide Web относится и система HotBot, содержащая сведения о полных текстах 54 миллионов страниц. HotBot принадлежит к новейшим системам, и ее углубленный поиск Expert Search дает поразительно широкие возможности для детализации запроса. Это достигается за счет использования многоступенчатого меню, предлагающего различные варианты составления поискового предписания. Можно осуществить поиск по наличию или сочетанию в документе нескольких терминов, поиск по отдельной фразе, поиск конкретного лица или электронного адреса. Для детализации запроса возможно применение условий SHOULD («может содержать»), MUST («должен обязательно содержать») и MUST NOT («не должен содержать») по отношению к каким-либо понятиям. Кроме этого, HotBot предоставляет возможность ограничить поиск по дате создания или последнего обновления документа, по географическому местоположению сервера, по типу искомых файлов, и т.д. Система имеет понятный и удобный интерфейс и допускает поиск на русском языке. Единственным ее недостатком является, пожалуй, отсутствие возможности усекать окончания ключевых слов.
Система WebCrawler относится к ветеранам сетевого поиска, поэтому ее синтаксис несколько беднее, чем в современных разработках. В поисковом предписании используются лишь знаки «+» и «-». Первый ставится перед словом, которое обязательно должно присутствовать в документе, а второй -перед термином, появление которого в искомом тексте должно быть исключено. WebCrawler является одним из немногих средств, простирающих свои «интересы» за пределы WWW и Usenet на узлы, поддерживающие Gopher-, FTP- и Telnet-приложения, – в некоторых случаях это заметно расширяет поиск.
Различия в стратегии, широте охвата и просто в мощности разных систем порой приводят к тому, что описанные поисковые средства дают разноречивые ответы на один и тот же запрос. Этим не замедлили воспользоваться разработчики поисковых орудий особого рода, основанных исключительно на применении потенциала других поисковых систем. К таковым, в частности, относится MetaCrawler, главное достоинство которого заключается в умении рассылать вводимые в него запросы по другим системам, а затем суммировать результаты. Таким образом, пользователь, вводя поисковое предписание в MetaCrawler, фактически одновременно обращается к десятку различных поисковых систем. Этим гарантируется «объективность» полученных результатов, но из-за уже упоминавшихся различий в подходах к обработке терминов разными системами результат может оказаться не всегда релевантным запросу.
К сожалению, общим «недостатком» зарубежных систем является обращение только к наиболее известным российским серверам. В этой связи всем отечественным Web-мастерам стоит посоветовать не лениться пользоваться функцией «добавить адрес» (Add URL или Submit URL), которая есть во всех перечисленных системах, дабы самостоятельно дать о себе знать мировому сообществу и «подписать» программы-роботы на регулярное сканирование и индексирование своих страниц.
Если зарубежные системы рассчитаны на поиск сведений в Интернете независимо от языка издания, то российские поисковые средства нацелены на выявление прежде всего русскоязычных источников.
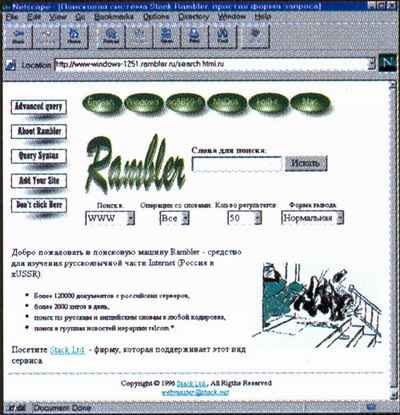
Наиболее мощным из них является Stack Rambler – система, созданная специально для поиска материалов на серверах в пределах бывшего СССР. Ее механизм предусматривает поиск с использованием операторов AND и OR, a также позволяет усекать окончания с использованием традиционных знаков «*» или «?». Щелкнув по надписи «Детальный запрос», можно уточнить поисковое предписание по дате последнего обновления документа и указать термины, появление которых в источнике должно быть исключено (по сути, это дополнительный булев оператор NOT). Stack Rambler обеспечивает близкий к образцовому вывод результатов поиска, превосходящий, на мой взгляд, все зарубежные аналоги. Даже в нормальной форме (а есть еще детальная!) ссылка включает, помимо названия, электронного адреса, размера и времени обновления документа, еще и внушительных размеров резюме, из которого можно получить представление о том, в каком контексте употреблены искомые термины (они выделены жирным шрифтом).
Stack Rambler работает чрезвычайно быстро. И хотя опытное ее опробование показало, что она не является полнотекстовой, глубина просмотра Web-страниц вполне достаточна для выявления большого количества информации.
«Новый русский поиск» в полнотекстовом режиме обследует более шестидесяти наиболее информативных российских серверов, а также содержание всех некоммерческих конференций «Релком» за последние две недели. При этом система может вести поиск с использованием операторов AND, OR и NOT, допускает усечение окончаний и поиск подряд стоящих терминов, соединяемых знаком«+». Скорость работы «Нового русского...», к сожалению, недостаточно высока, а результаты поиска не содержат какого-либо резюме – только название, электронный адрес, время последнего обновления документа и степень его соответствия запросу.
Поисковое средство с симпатичным названием «Паук» имеет в своем арсенале возможность поиска только по названиям, первым строкам текста (комментариям) и электронным адресам Web-страниц, с возможностью усечения окончаний – «*». Увы, система не позволяет употреблять даже простейшие логические операторы AND или OR, поэтому поиск ведется одновременно только по одному понятию. «Паук» снабжен справочником наподобие широко известного Yahoo! по российским ресурсам, однако его наполнение и логика систематизации пока оставляют желать лучшего.
Добавим, что на некоторых наиболее значительных отечественных серверах представлены поисковые системы, осуществляющие поиск в пределах данного узла. Таковы, например, «Апорт!» (http://194.85.117.34/_find), обозревающий сервер «Агама», «Поиск по серверу» АОЗТ «Дукс» (http://www.dux.ru), и некоторые другие.
При работе со всеми поисковыми системами стоит обратить внимание на то, что в первую очередь, то есть в начале списка результатов, они выдают ссылки на документы, наиболее релевантные запросу. Рейтинг соответствия определяется на основе частоты употребления искомых терминов, их расположения в тексте, и т. д. Поэтому, когда результаты поиска исчисляются сотнями ссылок, высока вероятность, что наиболее интересные материалы будут содержаться в первых нескольких десятках.
Кроме того, многие системы обладают специальной функцией «похожие страницы» (в английском переводе -«Similar Pages», в «Новом русском поиске» – «Документы-образцы»). Она удобна для конкретизации результатов поиска, и ее смысл заключается в отборе документов, схожих по содержанию с конкретной Web-страницей. Так, например, при поиске сведений о А. И. Лебеде неминуемо обнаружатся ссылки на одноименного представителя семейства пернатых. Для того чтобы отсеять эти записи, надо на одной из ссылок, бесспорно относящихся к Лебедю-политику, указать названную функцию, то есть щелкнуть мышью на строку «похожие страницы».
К сожалению, некоторые поисковые системы при запросе, в котором содержится несколько терминов, порой руководствуются известным принципом «на безрыбье и рак рыба», выдавая вначале сведения о документах, включающих все термины, а затем и ссылки на Web-страницы, содержащие два из трех или даже один из трех искомых терминов. Системы как бы «забывают», что они обязаны сообщать данные только при условии сочетания всех слов, причем пользователи остаются в полном неведении относительно этой особенности.
С ростом объема русскоязычной части Интернета потребность в поисковых средствах будет все более возрастать. Нет сомнений, что в перспективе отечественные поисковые системы будут наращивать как аппаратно-программную мощность, так и искусственно-интеллектуальные способности, обеспечивающие выдачу более точного и взвешенного результата.