Технологии
Интелвидение будущего
Леонид Побережный
Вслед за выпуском новых ММХ-процессоров (Multimedia extension), обеспечивающих поддержку мультимедийных приложениай «изнутри», фирма Intel предлагает свое решение и «снаружи» – оптимизацию вывода графической информации посредством специализированного порта AGP (Accelerated Graphics Port).
Современные графические и видеоприложения предъявляют повышенные требования к быстродействию компьютерных систем. Трехмерная графика (30-графика) становится основным двигателем прогресса в этой области на следующие несколько лет. Как это было с шиной PCI, компания Intel энергично «проталкивает» AGP на компьютерный рынок. Она уже подписала соглашение с Microsoft, а также согласовала спецификацию порта с крупнейшими производителями видеокарт – ATI и Cirrus Logic. Все основные производители видеоакселераторов, такие как 3Dfx, SDIabs, ATI, Cirrus Logic, Rendation, S3 и Trident, планируют поддержать проект AGP. Первые графические карты с AGP должны появиться в начале 1997 года, а к концу года ожидается выпуск компьютерных систем высокого класса с AGP.
И повод для оптимизма есть. Ведь AGP позволяет «прогонять» графические данные почти в четыре раза быстрее сегодняшней шины PCI. К примеру, компания Number Nine планирует изготовлять 128-разрядные 20/30-аксе-лераторы (Imagine 128) именно в расчете на непосредственный доступ к системной памяти и высокую скорость передачи данных. Эндрю Найда (Andrew Najda), главный управляющий делами Number Nine, считает, что AGP открывает путь к достижению графики класса рабочей станции, a Imagine 128 обеспечит на стандартном PC кинематографическое качество изображения.
Трудно быть видеокартой
Прежде чем приступить к дальнейшему изложению, давайте определим некоторые термины.
Фрейм-буфером называется память, расположенная на видеокарте и являющаяся хранилищем видеоизображения.
Текстурными данными называются «материалы», отображаемые на 30-объектах (цвет, фактура и пр.). Для хранения текстур используется специальная текстурная память, также расположенная на видеокарте.
Информацию о «видимости» трехмерных поверхностей хранит z-буфер, также расположенный на видеокарте.
Итак, для того чтобы в вашей трехмерной игрушке виртуальный воин не размахивал попусту бластером, ожидая смены интерьера очередного зала боевых искусств, необходимо как можно быстрее «прокачать» информацию об этих изменениях между графическим акселератором и соответствующими областями памяти. Во многих графических подсистемах для этого используются дорогие быстродействующие чипы памяти, увеличивающие и стоимость компьютера. Вот тут-то и выявляется узкое место сегодняшних PC.
Во-первых, для повышения качества отображения 30-графики необходимо все больше и больше текстур, соответственно и текстурной памяти, поэтому размещение их в видеопамяти продолжало бы увеличивать стоимость графической подсистемы. И, что особенно грустно, эта память заведомо потеряна для системы в целом, поскольку имеет только целевое назначение (хранение текстур).
Во-вторых, текстурные данные довольно статичны по своей природе, и их все равно надо куда-то поместить на период работы конкретного 30-приложения.
Альтернативным решением этой проблемы стало бы перемещение текстур из памяти видеокарты в основную память. Такое перемещение позволило бы освободить ресурсы, которые могли бы использоваться другими элементами системы.
Однако быстрое наложение текстур на объекты в масштабе реального времени (например, в процессе игры) требует значительно большей пропускной способности, чем может предоставить шина PCI.
Как же Intel намерена решать эту задачу?
Что, и PCI уже не шина?
Кажется, совсем недавно была создана шина PCI, чтобы решить проблему пропускной способности в среде периферийных устройств, системной памяти и центрального процессора. Но не успели мы нарадоваться ею, как Intel пришла к выводу, что сегодняшняя архитектура PC должна быть модифицирована для обеспечения все возрастающих требований 3D-графики.
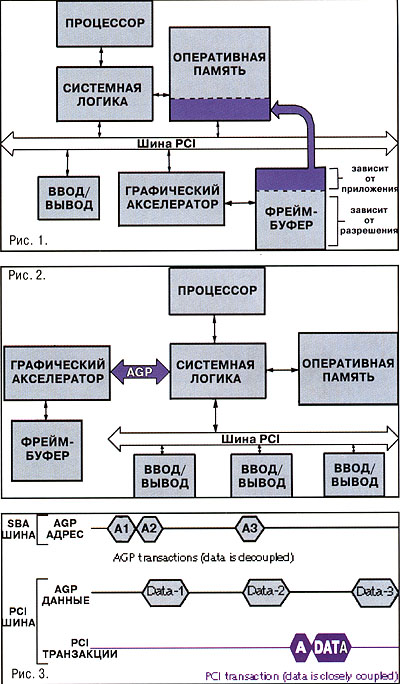
Продолжая развитие новых стандартов в системотехнике, Intel собирается установить на материнской плате специализированный графический порт – AGP, что, по ее мнению, позволит преодолеть ограничения, присущие архитектуре PCI, -потери на циклах ожидания и недостаточную пропускную способность при отображении трехмерной графики. То есть AGP – специализированная надстройка над шиной PCI, позволяющая создать скоростной канал обмена данными между графическим акселератором и системной логикой PC. При этом прожорливые текстурные данные вместо драгоценной видеопамяти «отъедят» кусочек основной. См. рис. 1.
Итак, AGP-расширение основной PCI-архитектуры основывается на трех китах: многоканальной шине адреса, конвейерной обработке данных и рабочей частоте шины 133 МГц. Для того чтобы достигнуть высокой скорости передачи, AGP определен как непосредственное или прямое соединение (point-to-point), а не через общую шину. См. рис. 2.
Как видно, новая подсистема связана с памятью и процессором через системное логическое устройство и предназначена исключительно для графики, причем эта система поддерживает графический контроллер как на материнской плате, так и на внешней графической карте.
PCI не догоняет...
Непосредственное соединение двух оконечных устройств, несомненно упростит задачу синхронизации, улучшит целостность данных, упростит AGP-протоколы и устранит арбитражные потери, присущие шине PCI. Как видно из рис. 2, системная архитектура предлагаемого порта, добавляя высокоскоростной маршрут между графической подсистемой и системной памятью, не оказывает влияния на любой другой периферийный порт.
При этом Intel пытается в трансляционном отношении сохранить в значительной мере часть PCI-cпeцификации, особо избегая использования любой из зарезервированных областей и штырьков в PCI-спецификации. Большинство PCI-сигналов используется в AGP-командах, но, по сравнению с PCI, добавлено еще 16 сигналов, ответственных за расширенные функции AGP. Специфические AGP-протоколы, подобно конвейеру, перекрываются на PCI таким образом, что для стандартного устройства в шине PCI «надстройка» AGP «прозрачна». Тем не менее всем AGP-устройствам потребуется отвечать на PCI-запросы, поэтому они должны оперировать едиными сигналами, как определено спецификацией PCI.
Несмотря на совместимость AGP и PCI, они предназначены для различных устройств. Главная причина в том, что AGP – это не шина в широком смысле и поддерживает единственное графическое устройство.
Если бы Intel пыталась сформировать AGP как расширенный набор PCI, устанавливая AGP-устройства в этой шине, то это решение должно было или ограничить AGP частотой 33 МГц, или обязать все PCI-устройства поддерживать 66 МГц, удорожая большинство периферийных устройств.
Кроме того, AGP определяет собственный слот, отличный от PCI, и многоканальная адресация сигналов не должна приспосабливаться к существующему PCI-слоту.
Значительная совместимость с PCI-шиной позволила Intel разработать спецификацию на AGP очень быстро (само понятие AGP не существовало еще восемь месяцев тому назад).
Сходство с PCI также упростит задачу разработчиков аппаратных средств. В течение следующих нескольких лет многие графические чипы, вероятно, будут носителями двойного AGP/PCI-интерфейса, давая системному разработчику больше гибкости. Фактически, некоторые первые графические AGP-чипы могут быть просто модифицированными PCI-чипами.
Прямой доступ – на конвейер
Конвейер данных – основное расширение протокола, предусматриваемое AGP. Но только операции чтения и записи, инициируемые видеоускорителем и направленные в основную память, поставлены на конвейер. Системная логика может иметь доступ к графическому чипу только по стандартам PCI-протокола. Все операции шины, включая чтение и запись, обращенные в графический контроллер, выполнены как стандартные PCI-запросы.
Конвейерная обработка данных, определяемая AGP, работает по методу разделения трансакций (групповые операции чтения/записи). Рассмотрим это на примере чтения из системной памяти.
Графический чип выдает запрос на конвейерную обработку(запрос доступа) в чип системной логики. Системная логика отвечает на запрос и обеспечивает затем передачу данных из основной памяти. Графический чип, не дожидаясь получения предшествующей порции данных, выдает следующий запрос. Это перекрытие результатов и обеспечивает конвейер различных запросов(чтения или записи), причем очередь запросов всегда активна (на то он и конвейер). Что особенно важно, AGP-спецификация не навязывает предела длины очереди запросов, этот предел определяется возможностями системной реализации. Для конвейерной AGP-обработки характерна несвязанность фаз адреса и данных. См. рис. 3.
AGP-133
Другое важное различие между AGP и PCI – техника двойной синхронизации, используемая для достижения скорости передачи данных с тактовой частотой 133 МГц. Непосредственное соединение графического акселератора и чипа системной логики упростит не только электрическую среду их взаимодействия, но и обеспечит хорошее нагрузочное согласование. Таким образом, открывается возможность осуществлять синхронизацию от импульсов одного и того же задающего тактового генератора частотой 66 МГц как по переднему фронту импульса, так и по заднему. За счет этого и появляется возможность синхронизации по стробам 66 МГц и 133 МГц.
При этом передача данных на частоте 66 МГц соответствует некоторой расчетной спецификации 66 МГц шины PCI, а режим AGP-133 требует дополнительного интерфейса. Как видно на рис. 3, Intel добавляет 8-разрядную адресную шину (SBA Bus), причем адреса и данные демультиплексированы, а адресация по шине SBA служит исключительно для передачи AGP-запросов доступа в системную память.
На частоте 133 МГц AGP достигнет максимальной пропускной способности 533 Мбайт/с. Для сравнения, в шине PCI на тактовой частоте 33 МГц обеспечивается максимальная производительность лишь 132 Мбайт/с.
А вот и ложка дегтя! Очевидно, что принцип двойной синхронизации предъявляет особые требования к качеству импульсов задающего генератора. Не потребует ли это дополнительных схемотехнических решений и, следовательно, затрат?
AGP: увидел – купи!
Текстурные данные, которые планируется загружать в основную память, должны быть непрерывными с точки зрения трехмерного приложения и графического акселератора. Типичная текстура размерностью 256x256 пикселов и 16 бит на цвет занимает 128 Кбайт, и сколько таких текстур! Как разместить их непрерывно в физической памяти? Windows такой возможности не предоставляет.
Решение Intel: надо расположить текстурные данные в системной памяти постранично по 4К, а информацию об их местоположении поместить в некую область памяти – карту текстуры, и затем распределить эти участки в физической памяти (здесь прослеживается явная аналогия с формированием FAT – file allocation table на винчестере). Таблицу такого перевода виртуального адреса в физический Intel назвал GART (Graphics Address Remapping Table).
Intel в AGP установит чип, в котором и будет «рождаться и жить» эта самая GART. Этот чип назван 440LX и разрабатывается для взаимодействия с процессором Klamath. GART потенциально довольно велик. Описание 4 Мбайт текстурных данных требует 1024 записи по 4 байта каждая.
Логическая спецификация AGP не описывает, как GART будет формироваться этим чипом. Взамен поставщик такого чипа должен обеспечить его драйвером, управляющим GART согласно вызовам API (Application Programming Interface), которые будут определены в AGP-спецификации. Такой подход должен помочь другим поставщикам в разработке AGP-устройств, совместимых с Intel на системном уровне.
Подробные определения GART и соответствующего приложения API еще не доступны, и это может несколько задержать разработку чипа другими поставщиками. Вероятно, этой небольшой уловкой Intel хочет обеспечить себе фору на будущем рынке, «проталкивая» процессор Р6 с MMX-расширением и затягивая поддержку для процессоров Pentium. Одновременный выход на рынок AGP и процессора Р6 с ММХ обеспечит Intel отрыв от своих ближайших конкурентов -Cyrix с ее процессором 586дх и NexGen-AMDc Кб, также имеющих в своем составе мультимедийное расширение.
Тандем с Microsoft значительно укрепляет позиции проекта AGP. Microsoft объявила о доработке к концу года Windows 95 и Windows NT с целью обеспечения поддержки устройств, подключенных к новому порту, а ко второму кварталу 1997 года планирует расширить API-стандарт Direct Draw новой версией DirectX 5 специально для порта AGP.
И последнее, Intel и сама не прочь «побаловаться» с акселераторами, планируя в следующем году выпустить свой первый продукт – AGP 3D Accelerator. Для этой цели образован альянс с компанией Lockheed-Martin, имеющей богатый опыт в авиационном моделировании по технологии 3D. Итак, AGP – не универсальное решение, а средство оптимизации видеографики путем более полной реализации возможностей графических акселераторов. Это новшество, например, никак не скажется на быстродействии шины PCI, нынешнее состояние которой вполне удовлетворяет большинству неграфических устройств.