Тема номера
Уроки машинного чтения от Cognitive Technologies
Николай Никольский
Долгое время для многих пользователей компания Cognitive Technologies ассоциировалась лишь с разработками систем оптического распознавания текстов. Но в последнее время нам удалось значительно расширить спектр применения OCR и разработать новые, отвечающие требованиям рынка продукты и технологии. Однако сегодня нас интересуют именно системы OCR, их устройство и принципы функционирования. А начнем мы с самого простого случая распознавания – «гладких» текстов.
«Гладкие» тексты
Проблема распознавания текстов часто ассоциируется с распознаванием именно «гладких» текстов, поэтому рассказ об особенностях наших технологий, вероятно, стоит начать в русле этой традиции. Работает система по принципу «одной кнопки». Это означает, что при нажатии кнопки «Сканируй и Распознавай» запускается весь процесс обработки документа: сканирование, фрагментация страницы на текстовые и графические блоки, распознавание текста, проверка орфографии и формирование выходного файла. Но что за всем этим стоит? Интеллектуальный алгоритм позволяет автоматически подобрать оптимальный уровень яркости сканера (адаптивное сканирование) в зависимости от фона документа, сохранить иллюстрации (или, в зависимости от решаемой задачи, удалить ненужные графические элементы ря максимального сокращения последующего редактирования). Заглянем внутрь системы Cunei-Form'96 (или OCR-системы MacTiger для Macintosh) и посмотрим, каким же образом ей удается «понимать» текст. За распознавание текста отвечает целый ряд модулей(сканирование, выбор яркости, предобработка документа, фрагментация и др.), каждый из которых решает свою задачу. Интереснее всего для нас сегодня, разумеется, модуль распознавания.
На вход модуля поступает полученное после сканирования изображение. Теперь необходимо сопоставить каждому элементу изображения символ ASCII-таблицы (то есть получить собственно текст, готовый для редактирования).
В CuneiForm используется несколько методов подобного сопоставления. Во-первых, образ каждого символа раскладывается на отдельные элементы – события. К примеру, событием является фрагмент от одной линии пересечения до другой. Совокупность событий представляет собой компактное описание символа.
Другие методы основаны на соотношении «масс» отдельных элементов символов и описании их характерных признаков (закругления, прямые, углы и т. д.). По каждому из этих описаний существуют базы данных, в которых находятся соответствующие эталоны. Поступающий на обработку элемент изображения сравнивается с эталоном. А затем на основании этого сравнения решающая функция выносит вердикт о соответствии изображения конкретному символу.
Кроме того, существуют алгоритмы, которые позволяют работать с текстами низкого качества. Так, для разрезания «склеенных» символов существует метод оценки оптимальных разбиений (наши ноу-хау – технологии FustCut и PowerCut). И напротив, для соединения «рассыпанных» элементов разработан механизм их соединения.
В CuneiForm'96 мы впервые применили алгоритмы самообучения (или адаптивного распознавания). Принцип их работы состоит в следующем.
В каждом тексте присутствуют четко и нечетко пропечатанные символы. Если после того как система распознала текст (как это делает обычная система, например предыдущая версия OCR CuneiForm 2.95), выясняется, что точность оказалась ниже пороговой, производится дораспознавание текста на основе шрифта, который генерируется системой по хорошо пропечатанным символам. Здесь разработчики соединили достоинства двух типов систем распознавания: омни- и мультишрифтовые. Напомним, что первые позволяют распознавать любые шрифты без дополнительного обучения, вторые же более устойчивы при распознавании низкокачественных текстов.
Результаты применения CuneiForm'96 показали, что использование самообучающихся алгоритмов позволяет поднять точность распознавания низкокачественных текстов в четыре-пять раз! Но главное, пожалуй, в том, что самообучающиеся системы обладают гораздо большим потенциалом повышения точности распознавания.
Важную роль играют методы словарного и синтаксического распознавания и, по сути, служат мощным средством поддержки геометрического распознавания. Но для их эффективного использования необходимо было решить две важные задачи. Во-первых, реализовать быстрый доступ к большому (порядка 100000 слов) словарю. В результате удалось построить систему хранения слов, где на хранение каждого слова уходило не более одного байта, а доступ осуществлялся за минимальное время.
С другой стороны, потребовалось построить систему коррекции результатов распознавания, ориентированную на альтернативность событий (подобно системе проверки орфографии).
Сама по себе альтернативность результатов распознавания очевидна и обусловлена хранением коллекций букв вместе с «оценками соответствия». А словарный контроль позволял изменять эти оценки, используя словарную базу. В итоге применение словаря позволило реализовать схему дораспознавания символов.
Сегодня наряду с задачами повышения точности распознавания на передний план выходят вопросы расширения сфер применения OCR-технологий, соединения технологий распознавания с архивными системами. Иными словами, мы переходим от монопрограммы, выполняющей функции ввода текста, к автоматизированным комплексам, решающим задачи клиента в области документооборота. Вот уже около полугода CuneiForm поставляется в комплекте с сервером распознавания CuneiForm OCR Server, предназначенным для коллективного ввода данных в организациях, а электронный архив «Евфрат», включающий модуль распознавания, за короткое время приобрел большую популярность.
С таким прицелом создавался и комплект CuneiForm'96i Professional, существенно изменивший представления о системах распознавания в целом.
Наш спектр
Сегодня пользователи Internet, используя технологии Cognitive Technologies, уже могут преобразовывать бумажные документы непосредственно в формат HTML (с сохранением иллюстраций и таблиц), возможен прямой экспорт результатов распознавания в любой популярный браузер – например, Netscape Navigator или MS Internet Explorer. При этом CuneiForm '96i устраняет массу лишних действий и позволяет использовать все возможности профессиональной OCR-системы при подготовке документов для Internet/Intranet. Таким образом, OCR выступает в новом качестве: это не только альтернатива клавиатурному набору, но и окно в Internet.
Дополнительная утилита Cognitive FaxReader позволяет автоматически обрабатывать приходящие на факс-модем сообщения. До сих пор обработка факсов занимала недопустимо много времени. Каждое полученное факсимильное сообщение приходилось либо поочередно распознавать(для последующего хранения, отправки по электронной почте и т. д.), либо вообще хранить графическое изображение (что требовало места на диске и создавало массу неудобств в работе).
Теперь же применение Cognitive FaxReader позволяет избежать потерь времени на обработку (здесь используется MS Exchange for Windows 95) входящих факсимильных сообщений.
С вводом иллюстраций и таблиц OCR CuneiForm научилась справляться уже довольно давно -нужно лишь установить соответствующие опции в меню, причем система автоматически проводит поиск и распознавание таблицы.
Однако самым любопытным является, вероятно, все, что касается работы с ценными бумагами. По крайней мере, это наиболее показательные сюжеты. В 1994 году Cognitive Technologies разработала систему ввода цифровой информации (номеров) ценных бумаг Stock Tiger, которая использовалась для автоматического ввода больших объемов ваучеров.
Достаточно было положить пачку документов в автоподатчик сканера, нажать клавишу – и на экране появлялся распознанный текст. Важно, что здесь была решена довольно сложная проблема отделения полезной текстовой информации от гербового фона бумаги.
«Снять фон» можно двумя путями: с помощью установки цветного фильтра в сканирующее устройство или программными методами. Но у ценных бумаг гербовый фон не однороден, имеет различную цветовую гамму, и разработчики CuneiForm остановились на программном решении.
При сканировании в режиме 16 градаций «серого» (4 бита на точку) производились «срезы» цветных элементов и выделение данных, необходимых для дальнейшего распознавания. Собственно процесс распознавания проходил параллельно со сканированием ваучера и составлял не более 3-5 секунд на один ваучер. Здесь удалось добиться практически 100% по точности результата при вводе ваучеров.
Первая версия программы была установлена во многих банках и инвестиционных фондах.
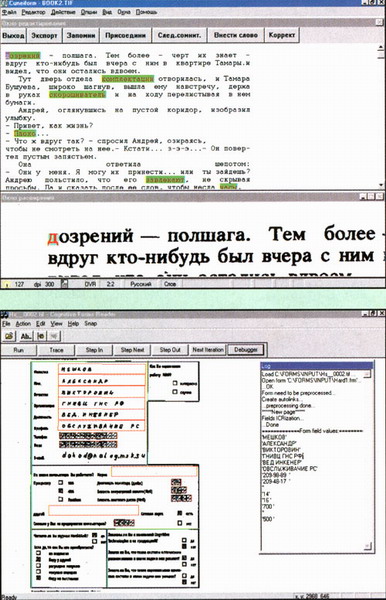
Отличной проверкой используемых нами технологий стала обработка визитных карточек.
Дело в том, что они практически не поддаются стандартизации. Поля -Ф.И.О., адрес, телефон и т. д. – располагаются произвольно. Более того, сам бланк может иметь не только произвольный размер, но и ориентацию (горизонтальную, вертикальную).
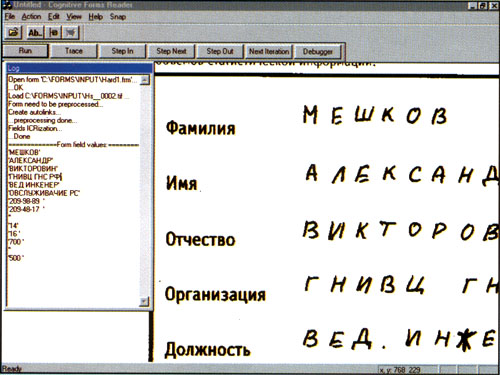
И все же Cognitive Technologies выпустила продукт Business Card Reader, позволяющий вводить русские, русско-английские и английские «визитки». После сканирования интеллектуальный алгоритм производит идентификацию полей (определяет, в каком поле находится название организации, в каком фамилия, в каком адрес, и т. д.), проводит их распознавание и отображает результаты (распознанный и готовый для редактирования текст и изображение).
Теперь пару слов о стандартных формах. Они используются в сферах, связанных с массовым обслуживанием клиентов. Для удобства обработки информация, содержащая ответ на один и тот же вопрос, на разных документах заносится в фиксированное поле. Одинаковый размер документов и фиксированное положение линий разграфки – вот основные отличия стандартной формы.
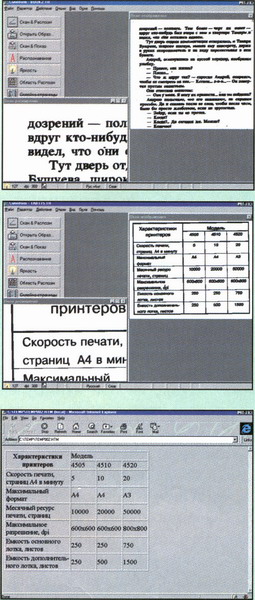
Однако, как ни парадоксально, стандартные формы не так легко поддаются распознаванию. Дело в том, что клиенты при заполнении формы, как правило, не обременяют себя качеством печати. Печатная машинка, матричный принтер или их вторая ксерокопия -примеры качества документов, с которыми пришлось столкнуться разработчикам систем автоматизации ввода форм. Но и это не все. Полезная текстовая информация часто попадает на линии разграфки.
В 1994 году компания Cognitive Technologies разработала систему оптического распознавания карт доходов (налоговых деклараций) для государственной налоговой инспекции республики Башкортостан. Предназначается она для потокового автоматизированного ввода деклараций в централизованную базу данных.
Добиться успешного решения было не просто. Главным препятствием, разумеется, оказалось низкое качество впечатанного текста. Заполнение бланков производилось, как уже говорилось, на пишущих машинках советского производства, так что характерными дефектами оказались неравномерная яркость пропечатки символов, а также искажения строк. К тому же, высокая яркость линий разграфки бланков затрудняла процесс распознавания.
Изначальный проект системы предполагал, что разграфка выполнена бледно-зеленым цветом и будет «снята» цветовым фильтром во время сканирования. Но определенные причины вынудили разработчиков решать проблему пересечения текста с линиями разграфки на программном уровне.
Откровенно говоря, здесь пришлось столкнуться с «российской действительностью». Работники типографии, печатавшей тираж деклараций, просто превысили концентрацию краски; в результате разграфка получилась ядовито зеленой, и снять ее не удалось бы никаким фильтром.
Но и эта задача была решена. Летом 1995 года разработчики сделали на международном симпозиуме по проблемам распознавания доклад, посвященный полученным при создании этой системы результатам, и получили высокую оценку.
Рукописи не горят. И не распознаются?
Очевидно, проблема распознавания рукописного текста значительно сложнее, чем в случае с текстом печатным. Если в последнем случае мы имеем дело с ограниченным числом вариаций изображений шрифтов (шаблонов), то в случае рукописного текста число шаблонов неизмеримо больше. Дополнительные сложности вносят также иные соотношения линейных размеров элементов изображений и т. п.
И все же сегодня мы можем признать, что основные этапы разработки технологии распознавания рукописных (отдельные символы, написанные от руки)символов уже пройдены. В арсенале Cognitive Technologies имеются технологии распознавания всех основных типов текстов: стилизованных цифр, печатных символов и «рукопечатных» символов. Но технологии ввода «рукопечатных» символов потребуется еще пройти стадию адаптации, после чего можно будет заявить, что инструментарий для потокового ввода документов в архивы действительно реализован полностью.
Резюме
Динамичное развитие новых компьютерных технологий (сетевые технологии, технологии «клиент-сервер», и т. д.) нашли свое отражение и в состоянии сектора электронного документооборота. Если раньше в продвижении технологий бесклавиатурного ввода делался упор на преимущества их персонального использования, то сегодня на первый план выходят преимущества коллективного и рационального использования технологий ввода и обработки документов. Иметь одну, обособленную систему распознавания сегодня уже явно недостаточно. С распознанными текстовыми файлами (как бы хорошо они распознаны ни были) нужно что-то делать: хранить в базе данных, осуществлять их поиск, передавать по локальной сети, и т. д. Словом, требуется взаимодействие с архивной или иной системой работы с документами. Таким образом, система распознавания превращается в утилиту для архивных и иных систем работы с документами.
С появлением сетевых версий систем сканирования (режим потокового сканирования OCR CuneiForm) и распознавания (сервер распознавания CuneiForm OCR Server) документов нашей компании уже удалось реализовать некоторые преимущества коллективного использования таких технологий в организациях разного масштаба.
По этой причине, с нашей точки зрения, актуальным был бы разговор о комплексном решении компаниями проблемы автоматизации работы с документами в организациях самого различного ранга. Что касается Cognitive Technologies, то представляемый ею электронный архив «Евфрат» (система включает в себя возможность ввода документов с помощью OCR CuneiForm), новые утилиты, встроенные в OCR CuneiForm'96, и технологии, используемые при реализации крупных проектов, продолжают линию компании, направленную на расширение применения систем ввода информации и разработку технологий автоматизации работы с документами.
С точки зрения специфики распознавания стоит выделить основные классы документов:
– «гладкие» тексты (собственно текст без графических иллюстраций и таблиц);
– документы со сложной топологией и графическими иллюстрациями (включая логотипы и подписи);
– таблицы;
– документы, напечатанные на гербовом фоне (ценные бумаги);
– документы с нестандартным расположением полей (визитные карточки и т. п.);
– стандартные формы (банковские и налоговые формы, страховые декларации);
– документы с рукописными символами (символы вписываются от руки в выделенных полях).
{НАЧАЛО ВРЕЗКИ}
Компания Cognitive Technologies основана в 1993 году на базе отдела искусственного интеллекта Института системного анализа. Руководителем отдела, и позже — компании, является д. т. н., профессор В. Л. Арлазаров. Сегодня в компании работают 95 человек, среди них 4 доктора и 6 кандидатов наук.
{КОНЕЦ ВРЕЗКИ}
{НАЧАЛО ВРЕЗКИ}
На момент написания статьи в широкой продаже находятся следующие версии систем распознавания Cognitive Technologies: OCR CuneiForm'96 for Windows, MacTiger 2.0 for Macintosh, Tiger 2.5 for DOS, BCR (Business Card Reader)1.1 for Windows, CuneiForm OCR Server 1.0 for Windows, а также электронный архив «Евфрат'96 for Windows».
{НАЧАЛО ВРЕЗКИ}