Тема номера
OCR изнутри внутри черного ящика, или Как устроена «распознавалка»
Константин Анисимович, Александр Шамис, Давид Ян
О технологии распознавания символов рассказывают разработчики системы FineReader.
Казалось бы, все просто
О существовании специальных систем, которые «автоматически вводят в компьютер текст», знают даже начинающие пользователи. Со стороны все выглядит довольно просто и логично. На отсканированном изображении система находит фрагменты, в которых «узнает» буквы, а затем заменяет эти изображения настоящими буквами, или, по-другому, их машинными кодами. Так осуществляется переход от изображения («фотографии») текста к «настоящему» тексту, с которым можно работать в текстовом редакторе. При этом, разумеется, «распознанный» текст занимает гораздо меньше места на диске, чем его отсканированный оригинал.
Итак, всем нам ясно, что распознавание текста состоит «всего навсего» в преобразовании изображения страшны в текст. Только вот добиться этого, оказывается, не так просто.
Компанией «Бит» была разработана специальная технология распознавания символов, которая получила название «фонтанного преобразования»1 , а на ее основе – коммерческий продукт, получивший высокую оценку как специалистов, так и пользователей. Это система оптического распознавания FineReader. Сегодня на рынке представлена уже третья версия продукта, которая работает не только с текстом, но и с формами, таблицами, а разработчики уже колдуют над новой, четвертой версией FineReader, которая будет распознавать не только печатный, но и рукописный текст. Как же все это работает?
Основные принципы, или целостность восприятия
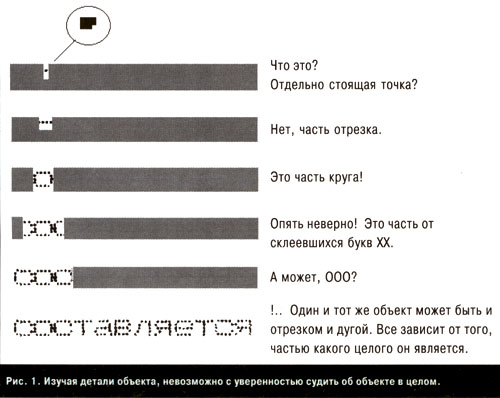
В основе фонтанного преобразования лежит так называемый принцип целостности. В соответствии с ним любой воспринимаемый объект рассматривается как целое, состоящее из частей, связанных между собой определенными отношениями. Так, например, печатная страница состоит из статей, статья – из заголовка и колонок, колонка- из абзацев, абзацы – из строк, строки – из слов и, наконец, слова – из букв. При этом все перечисленные элементы текста связаны между собой определенными пространственными и языковыми отношениями.
Для выделения целого требуется определить его части. Части же, в свою очередь, можно рассматривать только в составе целого (рис. 1). Поэтому целостный процесс восприятия может происходить только в рамках гипотезы о воспринимаемом объекте – целом.
После того как выдвинуто предположение о воспринимаемом объекте, выделяются и интерпретируются его части. Затем предпринимается попытка «собрать», «воссоздать» из них целое, чтобы проверить правильность исходной гипотезы. Разумеется, воспринимаемый объект может интерпретироваться в рамках более крупного целого.
Так, читая предложение, человек узнает буквы, воспринимает слова, связывает их в синтаксические конструкции и понимает смысл. При этом все процессы происходят одновременно, влияя друг на друга, а окончательное решение принимается на основе полного учета совокупности результатов. Например, иногда в результате полиграфического брака трудно идентифицировать букву (бывает, и не одну) только путем простого анализа изображения. Кроме того, нельзя априорно отдел ять текст от изображения или, например, бездумно делить строчки на слова, особенно в случае разрядки. И тем не менее человек, как правило, успешно справляется с такими задачами. Точно так же в технических системах подобные проблемы решаются с помощью специальных способов распознавания.
На самом деле любое решение при распознавании текста принимается не однозначно, а путем последовательного выдвижения и проверки гипотез с привлечением как знаний о самом исследуемом объекте, так и общего контекста.
Целостное описание класса объектов восприятия отвечает двум условиям: во-первых, все объекты данного класса удовлетворяют этому описанию, а во-вторых, ни один объект другого класса не удовлетворяет ему. Например, класс изображений буквы «К» должен быть описан так, чтобы любое изображение буквы «К» в него попадало, а изображения всех других букв – нет.
Такое описание обладает свойством отображаемости, то есть обеспечивает воспроизведение описываемых объектов: эталон буквы для системы OCR позволяет визуально воспроизвести букву, эталон слова для распознавания речи позволяет произнести слово, а описание структуры предложения в синтаксическом анализаторе позволяет синтезировать правильные и только правильные предложения. С практической точки зрения отображаемость играет огромную роль, поскольку позволяет эффективно контролировать качество описаний.
Существует два вида целостного описания: шаблонное и структурное.
В первом случае описание представляет собой изображение в растровом или векторном представлении, и задан класс преобразований (например, поворот, масштабирование и пр.).
Во втором случае описание представляется в виде графа, узлами которого являются составляющие элементы входного объекта, а дугами – пространственные отношения между ними. В свою очередь элементы могут оказаться сложными (то есть иметь свое описание), и так далее.
Конечно, шаблонное описание проще в реализации, чем структурное.
Однако оно не может использоваться для описания объектов с высокой степенью изменчивости. Шаблонное описание, к примеру, может применяться для распознавания только печатных символов, в то время как структурное – еще и для рукописных.
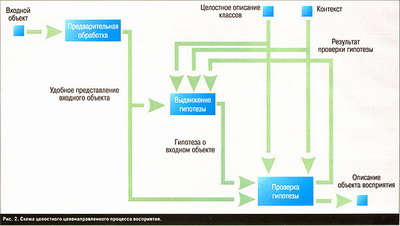
Целостность восприятия предполагает два важных архитектурных решения. Во-первых, все источники знания должны работать по возможности одновременно. Нельзя, например, сначала распознать страницу, а затем подвергнуть ее словарной и контекстной обработке, поскольку в этом случае невозможно будет осуществить обратную связь от контекстной обработки к распознаванию. Во-вторых, исследуемый объект должен представляться и обрабатываться по возможности целиком.
Первый шаг восприятия – это формирование гипотезы о воспринимаемом объекте. Гипотеза может формироваться как на основе априорной модели объекта, контекста и результатов проверки предыдущих гипотез(процесс «сверху вниз»), так и на основе предварительного анализа объекта («снизу-вверх»). Второй шаг – уточнение восприятия(проверка гипотезы), при котором производится дополнительный анализ объекта в рамках выдвинутой гипотезы и в полную силу привлекается контекст.
Для удобства восприятия необходимо провести предварительную обработку объекта, не потеряв при этом существенной информации о нем. Обычно предварительная обработка сводится к преобразованию входного объекта в представление, удобное для дальнейшей работы (например, векторизация изображения), или к получению всевозможных вариантов сегментации входного объекта, из которых путем выдвижения и проверки гипотез выбирается правильный.

Процесс выдвижения и проверки гипотез должен быть явно отражен в архитектуре программы. Каждая гипотеза должна быть объектом, который можно было бы оценить или сравнить с другими. Поэтому обычно гипотезы выдвигаются последовательно, а затем объединяются в список и сортируются на основе предварительной оценки. Для окончательного же выбора гипотезы активно используется контекст и другие дополнительные источники знания.
Распознаём символ
Сегодня известны три подхода к распознаванию символов – шаблонный, структурный и признаковый. Но принципу целостности отвечают лишь первые два.
Шаблонное описание проще в реализации, однако, в отличие от структурного, оно не позволяет описывать сложные объекты с большим разнообразием форм. Именно поэтому шаблонное описание применяется для распознавания лишь печатных символов, в то время как структурное – и для рукописных, имеющих, естественно, гораздо больше вариантов начертания.
Посмотрим, как устроены различные системы распознавания.
Шаблонные системы
Такие системы преобразуют изображение отдельного символа в растровое, сравнивают его со всеми шаблонами, имеющимися в базе2 и выбирают шаблон с наименьшим количеством точек, отличных от входного изображения. Шаблонные системы довольно устойчивы к дефектам изображения и имеют высокую скорость обработки входных данных, но надежно распознают только те шрифты, шаблоны которых им «известны». И если распознаваемый шрифт хоть немного отличается от эталонного, шаблонные системы могут делать ошибки даже при обработке очень качественных изображений!
Структурные системы
В таких системах объект описывается как граф, узлами которого являются элементы входного объекта, а дугами – пространственные отношения между ними. Системы, реализующие подобный подход, обычно работают с векторными изображениями.
Структурными элементами являются составляющие символ линии. Так, для буквы «р» – это вертикальный отрезок и дуга.
К недостаткам структурных систем следует отнести их высокую чувствительность к дефектам изображения, нарушающим составляющие элементы. Да и векторизация может добавить дополнительные дефекты. Кроме того, для этих систем, в отличие от шаблонных и признаковых, до сих пор не созданы эффективные автоматизированные процедуры обучения. Поэтому для FineReader структурные описания пришлось создавать вручную.
Признаковые системы
В них усредненное изображение каждого символа представляется как объект в n-мерном пространстве признаков. Здесь выбирается алфавит признаков, значения которых вычисляются при распознавании входного изображения. Полученный n-мерный вектор сравнивается с эталонными, и изображение относится к наиболее подходящему из них.
Мы уже отмечали, что признаковые системы не отвечают принципу целостности. Необходимое, но не достаточное условие целостности описания класса объектов (в нашем случае это класс изображений, представляющих один символ (состоит в том, что описанию должны удовлетворять все объекты данного класса и ни один из объектов других классов3. Но поскольку при вычислении признаков теряется существенная часть информации, трудно гарантировать, что к данному классу удастся отнести только «родные» объекты.
Секреты. Структурно-пятенный эталон
Фонтанное преобразование совмещает в себе достоинства шаблонной и структурной систем и, по нашему мнению, позволяет избежать недостатков, присущих каждой из них по отдельности. В основе этой технологии лежит использование структурно-пятенного эталона. Он позволяет представить изображения в виде набора пятен, связанных между собой n-арными отношениями, задающими структуру символа. Эти отношения (то есть расположение пятен друг относительно друга) образуют структурные элементы, составляющие символ. Так, например, отрезок – это один тип n-арных отношений между пятнами, эллипс – другой, дуга – третий. Другие отношения задают пространственное расположение образующих символ элементов. В эталоне задаются:
– имя;
– обязательные, запрещающие4 и необязательные структурные элементы;
– отношения между структурными элементами;
– отношения, связывающие структурные элементы с описывающим прямоугольником символа;
– атрибуты, используемые для выделения структурных элементов;
– атрибуты, используемые для проверки отношений между элементами;
– атрибуты, используемые для оценки качества элементов и отношений;
– позиция, с которой начинается выделение элемента (отношения локализации элементов).
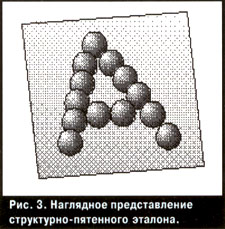
Структурные элементы, выделяемые для класса изображений, могут быть исходными и составными. Исходные структурные элементы – это пятна, составные – отрезок, дуга, кольцо, точка. В качестве составных структурных элементов, в принципе, могут быть взяты любые объекты, описанные в эталоне. Кроме того, они могут быть описаны как через исходные, так и через другие составные структурные элементы.
Например, для распознавания корейских иероглифов (слоговое письмо) составными элементами для описания слога являются описания отдельных букв (но не отдельные элементы букв).
В итоге, использование составных структурных элементов позволяет строить иерархические описания классов распознаваемых объектов.
В качестве отношений используются связи между структурными элементами, которые определяются либо метрическими характеристиками этих элементов (например, «длина больше»), либо их взаимным расположением на изображении (например, «правее», «соприкасается»).
При задании структурных элементов и отношений используются конкретизирующие параметры, позволяющие доопределить структурный элемент или отношение при использовании этого элемента в эталоне конкретного класса. Для структурных элементов конкретизирующими могут являться, например, параметры, задающие диапазон допустимой ориентации отрезка, а для отношений -параметры, задающие предельное допустимое расстояние между характерными точками структурных элементов в отношении «соприкасается».
Конкретизирующие параметры используются также для вычисления «качества» конкретного структурного элемента изображения и «качества» выполнения данного отношения.
Построение и тестирование структурно-пятенных эталонов для классов распознаваемых объектов – процесс сложный и трудоемкий. База изображений, которая используется для отладки описаний, должна содержать примеры хороших и плохих (предельно допустимых) изображений для каждой графемы, а изображения базы разделяются на обучающее и контрольное множества.
Разработчик описания предварительно задает набор структурных элементов (разбиение на пятна) и отношения между ними. Система обучения по базе изображений автоматически вычисляет параметры элементов и отношений. Полученный эталон проверяется и корректируется по контрольной выборке изображений данной графемы. По контрольной же выборке проверяется результат распознавания, то есть оценивается качество подтверждения гипотез.
Распознавание с использованием структурно-пятенного эталона происходит следующим образом. Эталон накладывается на изображение, и отношения между выделенными на изображении пятнами сравниваются с отношениями пятен в эталоне. Если выделенные на изображении пятна и отношения между ними удовлетворяют эталону некоторого символа, то данный символ добавляется в список гипотез о результате распознавания входного изображения.
Заключение
Сегодня FineReader используется для распознавания печатных текстов даже очень низкого качества. Векторизация изображения печатных текстов низкого качества дает плохие результаты, поэтому для системы FineReader был разработан структурно-пятенный эталон и технология его применения непосредственно к изображению букв (фонтанное преобразование). Высокое качество распознавания системы FineReader подтвердило правильность решений, выбранных разработчиками.
Задача распознавания слитного текста значительно сложнее задачи распознавания отдельных символов. Ее решение в нашей системе основано на взаимодействии структурного, признакового, растрового, дифференциального и лингвистического уровней. Но из-за ограниченности объема статьи основное внимание мы уделили главному -структурному уровню.
_____________________________
1 Слово «фонтанный» происходит от английского слова «font», что значит шрифт.
2 Базой называют совокупность шаблонов, используемых в системе.
3 Достаточным условием целостности описания является отображаемость описания.
4 Элементы, которые, будучи выделены на изображении, запрещают отнести его к данному классу.