Технологии
Дружба с умным алгоритмом
Армен Давтян
В пору начального развития практической кибернетики энтузиасты считали, что время, когда машина освоит мыслительные операции, сходные с человеческими, наступит буквально со дня на день. Для этого, во-первых, надо было самим уяснить алгоритмы мышления, а во-вторых, придать достаточную мощь компьютеру. Началось своеобразное соревнование "умников" и "силачей" – чей вклад в завтрашней технике будет больше.
К этой статье редакция считает необходимым сделать два примечания Во первых, конечно же, "КомпТек" и "Аркадия" – не единственные, кто разрабатывает технологии и продукты для анализа русского текста Назовем фирмы "Агама", Информатик" 'ПРОМТ", Cognitive Technologies – и это лишь первые, пришедшие на ум. Во-вторых разработчики, решающие аналогичные задачи для английского языка ни как не виноваты в том, что он легче поддается компьютерной обработке. Надо думать, они все таки делают то чего от них требует рынок.
Наш космический аппарат "Зонд" полетел к Луне, имея на борту небольшой бак с топливом плюс "Алгоритм трехимпульсного маневра Аксенова-Левантовского", реализованный в простеньком программном автомате. Американские "Аполлоны" отправлялись по тому же маршруту, оснащенные грубым переборным алгоритмом, "посаженным" на первый в мире бортовой компьютер, и с многотонным баком керосина. Неоптимальный алгоритм заставлял движок "Аполлона" тупо бороться с силами гравитации всю дорогу как туда, так и обратно, в то время как "Зонду" было достаточно – точно по часам -лишь четыре раза включить двигатель на несколько секунд.
К сожалению, негромкая победа умных алгоритмов над килобайтами, мегагерцами и тоннами керосина длилась очень недолго. А уж на пути к персональным компьютерам потерялось до обидного большое число идей, да и многие работы, направленные на добывание у разума и природы знаний о способах действия, попросту заглохли.
Ее величество Теория
Редкая по нынешним временам встреча с "умным" алгоритмом анализа русского текста ждала меня в софтверном подразделении компании "КомпТек" – фирме "Аркадия".
На самом деле полезность лексического анализа выходит далеко за рамки нынешнего применения компьютера вообще. Предвидя недоверчивое отношение к громким утверждениям, попробую начать с той практической задачи, которую решал в свое время автор системы "Ортодок" Аркадий Борковский, один из будущих основателей фирмы "Аркадия" грамматическая проверка текста на русском языке с согласованием слов в предложениях. В отличие от английского или китайского, русский являет собой пример языка, в котором установить связь между с словом и словоформой довольно сложно Формальными признаками здесь почти никогда обойтись не удается. Возьмите хотя бы словоформы "идти" и "шел", непонятно как (с лексической точки зрения) связанные для нас общим смыслом. С английским в этом смысле легче там "просто наизусть" достаточно помнить, ну, несколько десятков неправильных глаголов. Остальные-то – все правильные! С китайским таких проблем нет в принципе слова там вообще не имеют свойства принимать разную форму, смысл определяет лишь строгий порядок их следования.
Конечно, при анализе текста на любом языке не обойтись без словаря Однако на языках со множеством словоформ этот словарь должен быть устроен особым образом, иначе он окажется невероятно большим по объему. Возможность сжать словарь словоформ существует она основана на формализации наших знаний о словообразовании. Чем больше мы знаем о языке, тем компактнее можно представить словарь.
Упомянутая формализация – проблема в первую очередь научно-фундаментальная, а не практическая. Со одной стороны, была проделана кропотливая работа по созданию "инвертированного словаря", в котором словоформы расположены по алфавиту, но только не от первой к последней букве, а наоборот. Словарь А.А.Зализняка лег в основу многих отечественных систем грамматического разбора. Даже простой алгоритм перебора позволяет быстро найти в таком словаре нужную словоформу, поскольку концы слов отличаются друг от друга больше, чем их начала. С другой стороны, ученые не оставляли попыток по возможности формализовать правила словообразования, причем следовало сделать это так, чтобы алгоритм был способен не только генерировать предложения на естественном языке, но и восстанавливать смысл слов из словоформ и устойчивых выражений. Это сложнейшая научная область которой давно занимаются в Институте проблем передачи информации, в отделе под руководством Ю.Д.Апресяна В 70-х годах попытки формализации структуры текста на естественном языке делались неоднократно – как в трудах "чистых" лингвистов, так и в работах ученых, проводивших исследования на стыке наук, в частности, в рамках проблемы создания искусственного интеллекта. Уже тогда в разработках лаборатории Апресяна прослеживались две замечательные особенности. Во-первых, была тесная взаимосвязь между правилами лексического анализа и контекстом слова, а во-вторых, какой бы сложной ни оказывалась дедуктивная цепочка правил распознавания слов в тексте, в ее начале всегда лежали "внешние" признаки, доступные "пониманию" машины. Хотя не мне судить о достоинствах тех или иных лингвистических теорий, но по-моему, "компьютерное" направление в языкознании – одна из редчайших сфер науки, где каждый новый результат напрямую сулит массу пользы и удобств большому числу людей. Если, конечно, найдут того благодарного читателя, который возьмет на себя работу по реализации их в виде практических алгоритмов.
От теории к практике
У каждой культуры есть свои, особые, трудности с использованием компьютеров. Для англоговорящих лексический разбор – не самая первая из проблем. Действительно, если выделить то, что в тексте на английском языке заключено между одним пробелом и следующим (или знаком препинания), то это почти наверняка будет "английским словом". Да, конечно, не всегда. Но программы, строящиеся на этом простом правиле, оказываются вполне практичными. В русском же языке мы лишены подобной ясности, поскольку сформулировать правило узнавания русского слова можно только на основе знаний о правилах словообразования. Выходит, и компьютер для большинства из нас – помощник несколько менее ценный, чем для работающих на английском языке. Еще печальнее обстоит дело, когда речь идет о системах проверки орфографии и в особенности – о информационно-поисковых системах, выполняющих в других странах огромную полезную работу, какую у нас они выполнить не в состоянии. Давайте попробуем вообразить то огромное число людей, которых эти вопросы касаются непосредственно, и нам станет ясно, что самой важной проблемой взаимодействия русской языковой культуры и компьютерной техники является задача морфологического разбора русского текста.
Научные достижения в этой области практики всегда буквально рвали "из под пера" ученых, спеша воплотить их в ту или иную прикладную систему В 1993 году в фирме "Аркадия", созданной и руководимой Аркадием Воложем, разработали систему быстрого индексирования текста на русском языке, которая получила название "Яndex". При научной поддержке со стороны отдела компьютерной лингвистики Института проблем передачи информации авторам удалось так удачно реализовать алгоритмы анализа текста, что базовый словарь в 100 тысяч слов позволял распознавать не менее 2 миллионов словоформ.
Построить индекс не по словоформам, а по словам означает, между прочим, что программа несколько больше, чем другие, "понимает" прочитанный текст. Это заложенное в программу знание языка настолько эффективно, что сам словарь из 100 тысяч слов умещается всего лишь в 300 килобайт. Конечно, само по себе сжатие словаря не может быть целью создания столь сложной системы. В фирме "Аркадия", которая позднее стала софтверным подразделением "КомпТека", развитие алгоритмов распознавания русских слов шло на фоне создания целого ряда коммерческих программных продуктов. И наиболее ценным для меня в беседе с руководителем группы программирования Ильей Сегаловичем стало обретение нового взгляда на применения достижений языкознания в самых различных областях.
Одним из продуктов фирмы стала поисковая система по изобретениям Характеризуя практическую ценность интеллектуальных алгоритмов, обслуживающих запросы к базе описаний изобретений, достаточно сказать, что из такого, к примеру, запроса, как "колесный экипаж, управляемый мускульной силой человека", система способна узнать, что речь идет о велосипеде.
Для того чтобы это маленькое чудо стало возможным, текст при помещении в базу индексируется по всем входящим в него словам. Поступающий от пользователя запрос обрабатывается тем же алгоритмом, и производится отождествление. Этот серьезный подход столь разительно отличается от упрощенных схем, реализованных в популярных коммерческих программных системах, что, не приди на помощь последним лексическая простота английского языка, век их – по сравнению с высококлассной отечественной разработкой, – на мой взгляд, оказался бы очень недолгим.
Когда мы полюбим гипертекст
Чем компьютерное хранение текстовой информации лучше "бумажного"? Наверное, тем, что компьютер должен упрощать ее поиск и извлечение. Перенося в компьютер те или иные сведения, организовав систему их хранения, мы вправе рассчитывать на помощь машины, когда требуется найти нужный документ. Между тем на практике мы сталкиваемся с откровенным примитивизмом систем поиска, их полной непригодностью для обслуживания запросов на русском языке. Но этим наше вынужденное отставание не ограничивается. В системе помощи Windows, в программах, изготовленных с применением Microsoft Multimedia Viewer, среди гипертекстовых отсылок нас ждет свидание с коряво переведенными предложениями, возникшими на славной ниве русификации. И все потому, что для достижения однозначности переводчику приходится втискивать многочисленные словоформы в именительный падеж и неопределенную форму глагола.
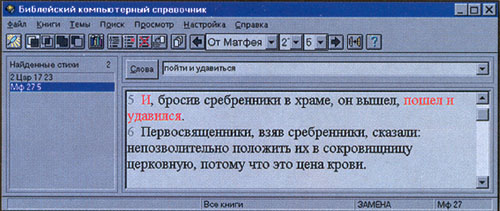
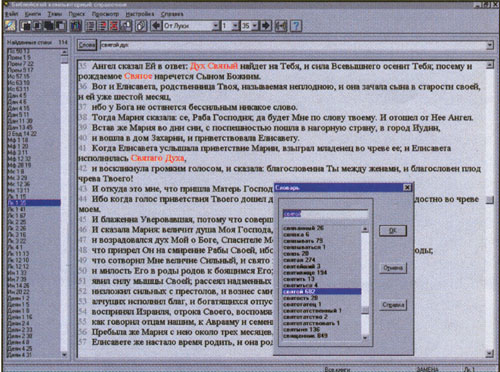
Можно в чем угодно уповать на передовой опыт других, но проблемы родного языка нам придется решать самим. И мне представляется, что для реализации этой задачи в фирме "КомпТек" выбрали беспроигрышную стратегию, которую стоит поставить в заслугу руководителю проектов Татьяне Захарьевне Логиновой: разработчики не ограничились созданием инструмента, а самостоятельно подготовили два информационных продукта, предназначенных для широкого распространения Первый – Библия. Здесь русский читатель впервые может сформулировать сложный запрос на русском языке, и поисковая система, доказывая попутно свою способность ориентироваться даже в библейских архаизмах, найдет искомый стих Второй продукт, созданный совместно с НПЦ "Информрегистр", называется "Грибоедов" Вот область, где забуксовали бы и англоязычные системы, рассчитанные лишь на разговорное подмножество языка!
К сожалению, для общего потока программных разработок ядро словарно-поисковой системы "flndex" – этакий "нежданный гость". Стыковать ее с готовыми гипертекстовыми системами напрямую не представляется возможным – хотя бы потому, что эти последние не делают отличия слова от словоформы Разработчикам под руководством А.Воложа пришлось (да нет же – посчастливилось!) создавать систему трансляции и отображения гипертекста практически с нуля. И наверняка это было к лучшему, поскольку авторам удалось реализовать собственный подход к построению такой системы, такой же основательный и "разборчивый", как и в случае с алгоритмами поиска.
В качестве базового языка разработчики остановили свой выбор на SGML – обобщенном языке разметки, претендовавшем не так давно на роль универсального языка для издательских систем (Одна из реализаций подмножеств этого языка, HTML, хорошо знакома многим по World Wide Web.) Важнейшей идеей SGML, пo мнению разработчика Ильи Сегаловича, является нацеленность языка на семантику, смысл текста, а не на его внешнее представление, а также его полная декларативность. Пускай самокритичность разработчиков заставляет их сокрушаться по тому поводу, что их реализация поддерживает пока лишь один шрифт, – само появление вполне приспособленной для русского языка гипертекстовой системы является настоящим событием в российской компьютерной культуре.
Если текст, который вчера можно было лишь "линейно" читать, не имея возможности ни провести настоящий поиск, ни собрать статистику, отныне можно совершенно автоматически обогащать сведениями о словоупотреблении, смысловых взаимосвязях, то только теперь, пожалуй, идея создания электронных изданий начинает приобретать разумное основание.
Чем сложнее – тем лучше
Разработчики "КомпТека" сделали большой шаг вперед и по сравнению с теми, кто реализовывал правила морфологического анализа в виде модулей проверки орфографии, и по сравнению с другими создателями систем полнотекстового поиска, поскольку не остановились на одной из этих задач. Заработала цепочка, в которой отечественные разработчики просто принуждены были все делать "своими руками" методика – раз, алгоритм -два, инструментальная система -три, информационные продукты – четыре Теперь каждый из слоев этого "технологического пирога" отражает специфику особой культурной реальности, имя которой – русский язык.
"Электронная Библия" уже ждет своих читателей на прилавках. К ее WWW-версии можно получить доступ по адресу http://www.cti.ru. К осени появится компакт-диск "Грибоедов". С сожалением предвижу сложности с маркетингом этих продуктов, которые, однако, способны подготовить читателей к новым возможностям компьютерного потребления информации на русском языке. Уже хорошо, если люди начнут задаваться вопросом: так ли полезен простой текстовый формат для представления русского текста? Появятся новые продукты, в которых поисковая система будет играть второстепенную роль. Да, это будет второстепенная, но живая, качественная подсистема поиска на русском языке, которую никто не будет замечать, но без которой уже не смогут обходиться.
Но у держателей алгоритма лексического разбора есть и другие перспективы. Например, реализация коммерческой встраиваемой гипертекстовой системы и соответствующих инструментальных средств. Или современные системы проверки орфографии. Появись такие средства – разработчики ни одной документальной системы, ни одного текстового электронного издания не захотели бы обойтись без них.
Наконец, сами алгоритмы. Сопровождение и совершенствование алгоритмов такого порядка может никогда не закончиться, отражая все новые наработки лингвистов. Вряд ли каким-либо "лобовым" способом можно избавиться от сложности правил лексического разбора. Да и разбор этот в случае русского языка чисто лексическим оставаться не обязан, это от русской словоформы до слова – долгий путь, а от русского слова до смысла – несколько ближе (лингвисты бы сказали: "парадигмы слов Уже, чем в английском языке").
Вот и выходит, что отечественные разработчики стоят на заветном пути к пониманию компьютером текста на естественном языке, – вопрос, который на Западе благополучно потонул в гонке мегагерц и мегабайтов. Но может быть, последнее слово в споре "умников" и "силачей" еще не сказано?