
Обзоры
ORACLE Data Warehouse – информационные системы нового поколения
Андрей Сахаров
Концепция
Что такое Data Warehouse? Чтобы более точно ответить на этот вопрос, давайте обратимся в прошлое. В области информационных технологий всегда существовали два основных, взаимно дополняющих друг друга направления развития – системы, ориентированные на оперативную обработку данных, и системы, предназначенные для аналитической работы с информацией.
Но до настоящего времени, говоря о большом числе реализованных решений в области информационных систем, мы обычно имели в виду системы первого класса, ориентированные на оперативную обработку или, точнее, на "переработку" данных.
Подобное опережающее развитие одного из направлений имеет объективные причины. Во-первых, на начальном этапе автоматизации любой организации требовалось навести порядок и автоматизировать трудоемкие и легко формализуемые рутинные процессы обработки данных. А именно на это и ориентированы оперативные системы. Во-вторых, и, может быть, это главное, аналитические системы в некотором смысле опередили свое время. Они предъявляют существенно более высокие требования к аппаратному обеспечению (производительность, память, диски), и для их реализации до самого последнего времени требовались чрезвычайно дорогостоящие (миллионы долларов) аппаратные решения. Это и привело к тому, что аналитические системы, став в некотором роде элитными, не получили массового распространения.
Но в последние годы ситуация начала изменяться. Достижения в области компьютерных и информационных технологий, появление достаточно дешевых и высокоскоростных аппаратных решений с SMP-архитектурой, повышение уровня оптимизации запросов и распараллеливания процессов обработки данных в системах управления БД позволили по-новому взглянуть на архитектуру и средства реализации аналитических систем (табл.1).
Именно этот взгляд и материализовался в виде концепции Data Warehouse. У ее истоков стоит W.H.Inmon, охарактеризовавший концепцию (в книге "Using Data Warehouse") как предметно-ориентированное, интегрированное, неизменное, поддерживающее хронологию собрание данных, предназначенное для поддержки управления.
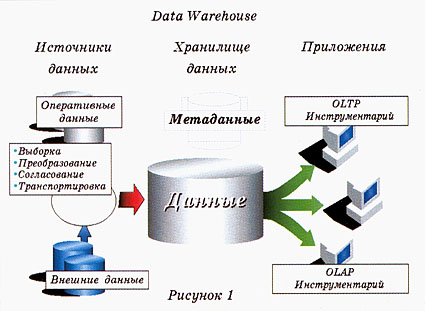
В основе концепции Data Warehouse лежат две идеи (см. рис. 1):
– интеграция ранее разъединенных данных (исторические архивы, данные из оперативных систем, общедоступные коммерческие данные) в едином информационном хранилище – "складе данных", их согласование и, возможно, агрегация;
– физическое разделение узлов, в которых реализуются оперативные системы, и узла, где выполняется аналитическая обработка данных.
Сегодня практически в любой организации можно найти то, что называется системами оперативной обработки данных. Подсистемы "Кадры", "Бухгалтерия", "Поставки", "Материально-техническое снабжение", реализованные на самых различных программных базах (начиная с FoxPro и Paradox и заканчивая ORACLE, RDB и DB2), исправно работают, плодя при этом многотомные архивы данных.
Основное назначение таких систем – оперативная обработка, они не могут позволить себе такую роскошь, как хранение исторических данных, скажем, за несколько месяцев. После своего устаревания информация выгружается в архивный набор и вычищается из оперативного хранилища.
Впрочем, эти бесполезные, с точки зрения оперативных систем, данные оказываются жизненно необходимы корпорационным менеджерам и аналитикам. Сегодня они, не имея доступа к подобной исторической информации, при анализе состояния и планировании дел вынуждены полагаться исключительно на собственный опыт и интуицию.
Какова динамика роста продаж телевизоров модели ABC за последние 14 месяцев в центральном регионе? Как долго за последние 2 года простаивал главный конвейер из-за отсутствия комплектующих с завода i 3?
Вот те простые вопросы, ответы на которые хранятся в исторических архивах и остаются невостребованными. И еще одна "порция" вопросов.
Сколько детей в возрасте от 5 до 12 лет проживает в северо-западном регионе? Какая сейчас средняя заработная плата в северо-западном регионе, как она изменилась за последний год в абсолютном размере и по отношению к доллару США? Сколько детских пальто было продано в данном регионе за последний год, какова динамика продаж по месяцам?
Очевидно, что для ответа на эти вопросы данных из оперативных источи ков явно недостаточно. Ибо труда предположить, чтобы швейная фабрика параллельно занималась еще и демографическими исследованиями.
Однако эти данные тоже доступны, и могут быть получены из различных источников, а затем интегрированы с собственной архивной информацией.
Основные особенности представления данных в Data Warehouse таковы:
– предметная ориентированность – все данные о некотором предмете (бизнес-объекте) собираются (возможно, из разных источников), согласовываются и представляются в единой, удобной для их использования в бизнес-анализе форме;
– интегрированность – данные согласованы и хранятся в едином общекорпоративном хранилище;

– неизменность – после внесения в общекорпоративное хранилище данные остаются неизменными и доступны только в режиме чтения;
- поддержка хронологии – данные хронологически структурированы и отражают историю за несколько лет.
В широком смысле, концепция Data Warehouse рассматривает не только вопросы организации хранения и доступа к данным, но и весь жизненный цикл системы. И хотя существуют различные подходы к построению Data Warehouse, можно выделить следующие ключевые этапы его построения:
– анализ информационных потребностей конечных пользователей;
– анализ потенциальных источников данных;
– определение целевых структур данных и регламентированных процедур преобразования и согласования исходной информации;
– загрузка информации в базу данных Data Warehouse;
– выборка, обработка и представление данных конечному пользователю.
Реализация
Одним из основных отличий (табл. 2) аналитических систем от традиционных оперативных систем обработки данных, помимо больших объемов хранимой информации, является то, что они в большей степени ориентированы на обработку произвольных, заранее нерегламентированных запросов. Вот почему при их создании фактически отсутствует этап проектирования регламентированных пользовательских приложений, наиболее ответственный и трудоемкий в традиционных оперативных системах.
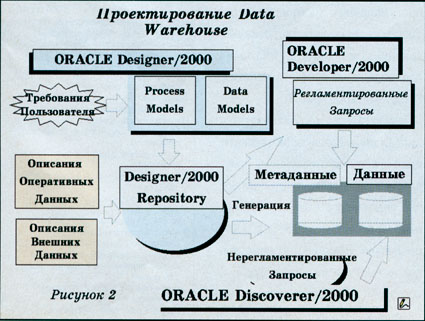
Однако, к сожалению, ничто не исчезает бесследно. Первой же задачей, с которой сталкиваешься при проектировании и реализации системы Data Warehouse (рис. 2), является необходимость одновременной работы с самыми разнородными источниками данных, несогласованностью их структур и форматов, масштабами архивов данных, которые должны быть переработаны и загружены в систему. И здесь реальную помощь проектировщику может оказать ORACLE Designer/2000, который обеспечивает возможность не только спроектировать и сгенерировать описания и собственно целевые структуры данных в БД ORACLE, но и описать структуры внешних данных, процессы их преобразования и определить места их реализации. При этом в качестве таких процессов могут выступать не только процедуры загрузки и преобразования данных, реализуемые собственно средствами ORACLE (хранимые PL/SQL-процедуры, функции, триггеры), но и процедуры преобразования данных, реализуемые средствами третьих фирм.
Исходная информация обычно хранится в разных местах и на разных носителях. Данные имеют неодинаковую структуру, формат, стандарты представления дат, денежных величин. Зачастую для обозначения одних и тех же объектов используются различные кодировки. Обычно в них отсутствуют реквизиты, идентифицирующие тот временной срез, которому они соответствуют, и источники их получения.
Прежде чем загружать подобные – "сырые" – данные в систему, они должны быть согласованы, отфильтрованы, дополнены информацией о времени и месте их получения и, возможно, агрегированы. И от того, насколько эффективно решены эти вопросы, насколько комфортны и производительны процедуры подготовки и загрузки, зависит в конечном счете успех или неудача Data Warehouse.
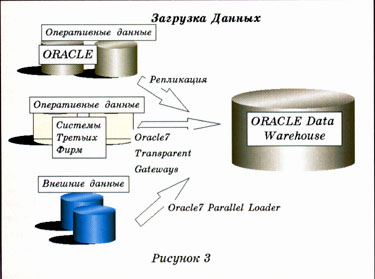
Откуда в Data Warehouse поступают данные? Проще сказать, откуда они не поступают. Оперативные системы, архивные файлы с историческими массивами данных, внешние общедоступные коммерческие данные (различного рода географические и демографические электронные справочники) – вот лишь некоторые источники получения информации (рис. 3).

Разнообразие потенциальных источников предполагает и многообразие возникающих проблем, а следовательно, прикладных программ и технологий обработки и загрузки данных.
На концептуальном уровне можно выделить три основных источника данных:
– данные, хранящиеся в оперативных базах, реализованных средствами ORACLE;
– данные, хранящиеся в оперативных базах, реализованных на основе СУБД третьих фирм;
– исторические архивные данные и различные распространяемые на коммерческой основе демографические, географические и статистические электронные справочники, каждый из которых использует собственную технологию выгрузки, обработки и загрузки данных (табл. 3).
Объемы данных в Data Warehouse имеют тенденцию к быстрому росту, поэтому традиционные способы хранения и выборки данных оказываются здесь малопригодными. Согласно опросам, средний планируемый объем базы данных для Data Warehouse составляет не менее 50 гигабайтов (более 50% опрошенных), а свыше 10% респондентов оценивает ее размер от 500 гигабайтов до 1 терабайта (может храниться не только структурированная, но и неструктурированная текстовая информация, многомерные пространственные данные, видео- и аудиоинформация).
ORACLE7 не только хранит все перечисленные выше типы данных и успешно поддерживает гигабайтные БД (табл.4), но и обеспечивает быстрый поиск и выборку как по заранее специфицированным проиндексированным полям, так и в неупорядоченных массивах данных (табл.5). Заметим, что данные в таблице 4 отражают статистику не по неким гипотетическим, а по реально работающим базам данных, реализованным как на ORACLE7, так и на ORACLE V6. В настоящее время максимальный объем БД, созданной средствами ORACLE?, составляет 4 терабайта.
Это обеспечивается при использовании многопроцессорных систем за счет поддержки различных методов доступа и индексации данных, эффективной оптимизации запросов (включая запросы типа "Звезда", наиболее трудоемкие и частые при аналитической обработке) и реального распараллеливания процедур выборки и обработки данных.
Средства анализа данных
Мало собрать информацию из разных источников и умело организовать ее хранение, надо уметь ею воспользоваться Здесь-то и лежит одно из основных отличий аналитических систем от традиционных оперативных систем обработки информации.
Основными пользователями Data Warehouse являются: среднее и высшее звено управления корпорацией, системные аналитики. Обычно это неординарно мыслящие люди, "не боящиеся" подойти к персональному компьютеру и достаточно эрудированные в области современных компьютерных технологий. Как показывает практика, только небольшая часть их информационных потребностей может быть заранее сформулирована, регламентирована и описана.
Основное требование подобной категории пользователей – иметь простой в освоении инструментарий, обеспечивающий возможность напрямую, без посредников, общаться с общекорпоративным хранилищем данных. Вот на таких специалистов и рассчитан ORACLE Discoverer/2000 (рис.4).
Основой Discoverer/2000 является Data Query, позволяющий любому, даже слабо подготовленному пользователю создавать отчеты, запросы и анализировать данные Построение запросов с помощью Data Query предельно упрощено, с помощью специального построителя формул, пользователь имеет возможность добавлять к запросу любые сложные функции. Результаты запросов и отчеты можно выводить не только на экран или печать, но и представлять в форме различных бизнес-диаграмм (столбчатых, полосовых, линейных, круговых).
С помощью ORACLE Discoverer/2000 неподготовленные пользователи легко могут понять общую концепцию и детали структуры базы данных. Для этого служит специальный уровень представления данных – End User Layer, поддерживающий взгляд на информацию как на совокупность множества бизнес-объектов. Такая возможность чрезвычайно важна для непрофессиональных пользователей, так как аналитику или менеджеру конкретные детали представления и организации данных в БД не интересны и даже могут мешать.
End User Layer позволяет конечному пользователю воспринимать модель данных в виде списка знакомых и естественных для него объектов, скажем, таких, как "Счета", "Годовая заработная плата", "Поставки". Кроме того, на этом уровне автоматически поддерживаются и обрабатываются любые отношения, таблицы (в том числе виртуальные) и т.д.



Более квалифицированные пользователи имеют возможность описывать с помощью построителя формул новые функции и представления и сохранять их для последующего применения.
Существенно, что запросы в Discoverer/2000 могут выполняться в фоновом режиме, что позволяет работать с несколькими различными приложениями (аналитическими запросами).
Аналитиков, для которых, собственно, и создается Data Warehouse, интересуют не только одномерные запросы (сколько продано телевизоров модели ABC? – здесь специфицируется только тип продукции), но и двумерные (сколько телевизоров модели ABC продано за последние 14 месяцев? – специфицируется тип продукции и временной интервал).
Обычно в аналитических запросах бывает больше двух измерений и внутренних связей. Несмотря на то что подобные запросы поддаются описанию (на основе традиционного реляционного подхода), делать это не всегда удобно Кроме того, как правило, желательно, чтобы все не ограничивалось констатацией фактов, которые происходили в прошлом, но и присутствовали разного рода прогнозы на будущее (запросы типа "Что будет, если..?").
Именно на это и сориентировано новое семейство программных продуктов фирмы ORACLE – ORACLE Express OLAP, включающее в себя: ORACLE Express Server, ORACLE Express Analyzer, ORACLE Exprees Objects, ORACLE Financial Analyzer, ORACLE Sales Analyzer. В основе перечисленных средств лежит концепция многомерного представления данных: пользователь считает, что его данные организованы не в виде плоских таблиц, а как многомерные (многослойные) массивы (рис. 5).
Некоторые рекомендации
Заключая обзор, хотелось бы сказать несколько слов о проблемах, с которыми чаще всего сталкиваются разработчики систем Data Warehouse, и дать некоторые рекомендации по выбору и развитию аппаратных платформ, на чьей основе он реализуется.
Одна из самых характерных ошибок при реализации систем такого класса – желание сделать все и сразу. Известны случаи, когда многомиллионные проекты, рассчитанные на несколько лет, оканчивались крахом. Совершенно иную модель реализации предлагает Inmon, стоящий у истоков концепции Data Warehouse. Согласно его модели, реализация системы должна осуществляется итерационно, небольшими шагами И первую отдачу (первый отчет) можно и нужно получить уже через 6-8 недель после старта работ.

Естественно, это будет только макетная модель будущей системы, но именно она поможет сформулировать и понять реальные информационные потребности менеджеров и аналитиков, выработать наиболее эффективные способы согласования, транспортировки и загрузки данных, определить уровни агрегации, методы хранения и доступа к информации. Кроме того, не следует начинать проект с закупки мощной техники. На первых порах будет достаточно компьютеров средней производительности с несколькими гигабайтами дисковой памяти. Однако не надо рассчитывать и на то, что сверхбольшие объемы данных будут эффективно обрабатываться на мини-компьютерах среднего класса. Дополнительные процессоры (табл. 6) и оперативная память (табл. 7) существенно повысят эффективность работы вашей системы.
